Что такое парсинг сайта, программы и примеры их использования

В интернет маркетинге часто необходимо собрать большой объем информации с сайта, не только со своего, но и с сайтов конкурентов, после её проанализировать и применить для каких-либо целей.
В статье постараемся достаточно просто рассказать о термине «парсинг”, его основных нюансах и рассмотрим несколько примеров его полезного применения, как для маркетологов и владельцев бизнеса, так и для SEO специалистов.
Что такое парсинг сайта?
Простыми словами парсинг – это автоматизированный сбор информации с любого сайта, ее анализ, преобразование и выдача в структурированном виде, чаще всего в виде таблицы с набором данных.
Парсер сайта — это любая программа или сервис, которая осуществляет автоматический сбор информации с заданного ресурса.
В статье мы разберем самые популярные программы и сервисы для парсинга сайта.
Зачем парсинг нужен и когда его используют?
Вообще парсинг можно разделить на 2 типа:
На основе полученных данных специалист составляет технические задания для устранения выявленных проблем.
Выше перечислены основные примеры использования парсинга. На самом деле их куда больше и ограничивается только вашей фантазией и некоторыми техническими особенностями.
Как работает парсинг? Алгоритм работы парсера.
Процесс парсинга — это автоматическое извлечение большого массива данных с веб-ресурсов, которое выполняется с помощью специальных скриптов.
Если кратко, то парсер ходит по ссылкам указанного сайта и сканирует код каждой страницы, собирая информацию о ней в Excel-файл либо куда-то еще. Совокупность информации со всех страниц сайта и будет итогом парсинга сайта.
Парсинг работает на основе XPath-запросов, это язык, который обращается к определенному участку кода страницы и извлекает из него заданную критерием информацию.
Алгоритм стандартного парсинга сайта.
Чем парсинг лучше работы человека?
Парсинг сайта – это рутинная и трудоемкая работа. Если вручную извлекать информацию из сайта, в котором всего 10 страниц, не такая сложная задача, то анализ сайта, у которого 50 страниц и больше, уже не покажется такой легкой.
Кроме того нельзя исключать человеческий фактор. Человек может что-то не заметить или не придать значения. В случае с парсером это исключено, главное его правильно настроить.
Если кратко, то парсер позволяет быстро, качественно и структурировано получить необходимую информацию.
Какую информацию можно получить, используя парсер?
У разных парсеров могут быть свои ограничения на парсинг, но по своей сути вы можете спарсить и получить абсолютно любую информацию, которая есть в коде страниц сайта.
Законно ли парсить чужие сайты?
Парсинг данных с сайтов-конкурентов или с агрегаторов не противоречат закону, если:
Если вы сомневаетесь по одному из перечисленных пунктов, перед проведением анализа сайта лучше проконсультироваться с юристом.
Популярные программы для парсинга сайта
Мы выделяем 4 основных инструменты для парсинга сайтов:
Google таблицы (Google Spreadsheet)
Удобный способ для парсинга, если нет необходимости парсить большое количество данных, так как есть лимиты на количество xml запросов в день.
С помощью таблиц Google Spreadsheet можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое.
Рассмотрим основные функции
Функция importHTML
Настраивает импорт таблиц и списков на страницах сайта. Прописывается следующим образом:
=IMPORTHTML(“ссылка на страницу”; запрос “table” или “list”; порядковый номер таблицы/списка)
Пример использования
Необходимо выгрузить данные из таблицы со страницы сайта.
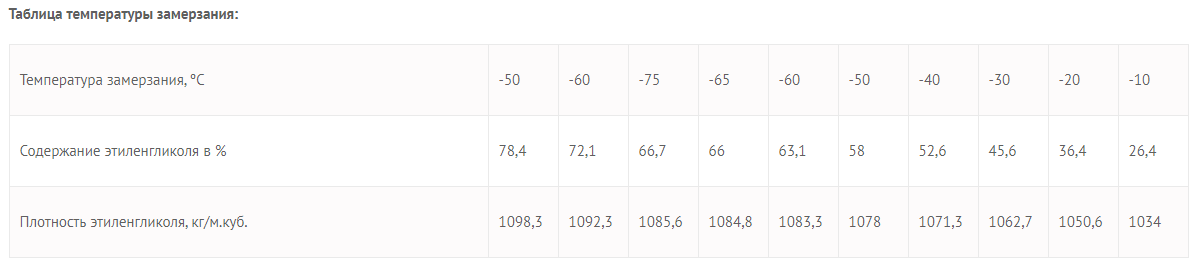

Для этого в формулу помещаем URL страницы, добавляем тег «table» и порядковый номер — 1.
Вот что получается:
Вставляем формулу в таблицу и смотрим результат:

Для выгрузки второй таблицы в формуле заменяем 1 на 2.
Вставляем формулу в таблицу и смотрим результат:
Функция importXML
Импортирует данные из документов в форматах HTML, XML, CSV, CSV, TSV, RSS, ATOM XML.
Функция имеет более широкий спектр опций, чем предыдущая. С её помощью со страниц и документов можно собирать информацию практически любого вида.
Работа с этой функцией предусматривает использование языка запросов XPath.
Формула:
=IMPORTXML(“ссылка”; “//XPath запрос”)
Пример использования
Вытягиваем title, description и заголовок h1.
В первом случае в формуле просто прописываем //title:
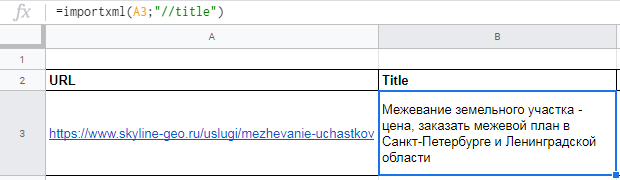
В формулу можно также добавлять названия ячеек, в которых содержатся нужные данные.
Для заголовка h1 похожая формула
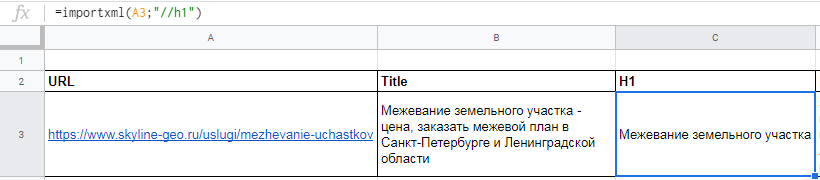
С парсингом description немного другая история, а именно прописать его XPath запросом. Он будет выглядеть так:

В случае с другими любыми данными XPath можно скопировать прямо из кода страницы. Делается это просто:
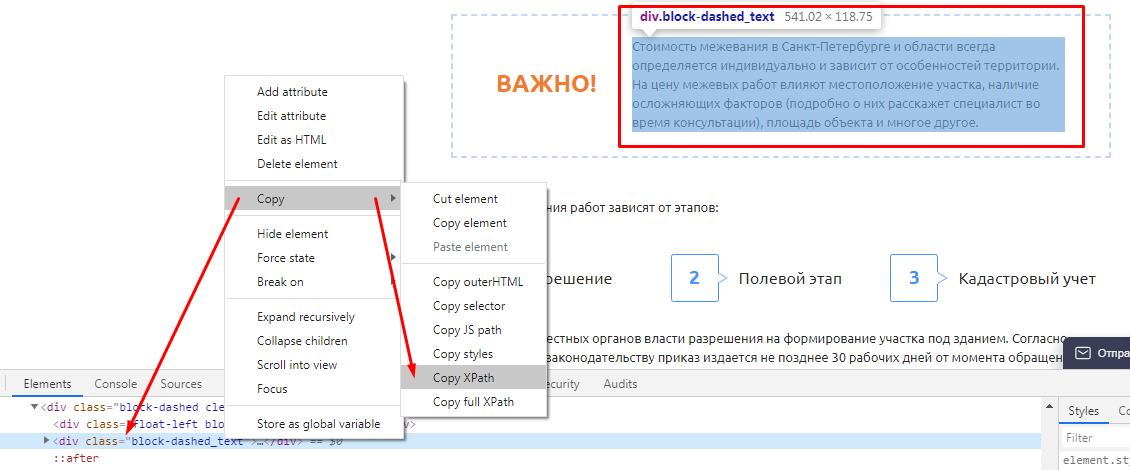
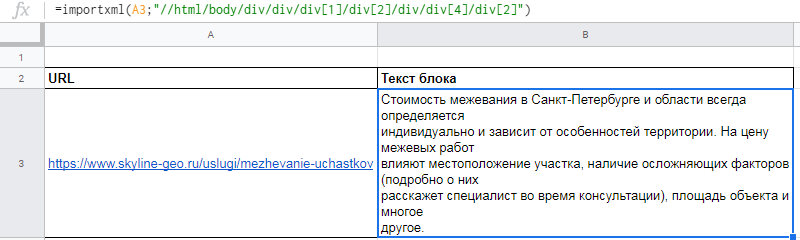
Вот как это будет выглядеть после всех манипуляций
Функция REGEXEXTRACT
С её помощью можно извлекать любую часть текста, которая соответствует регулярному выражению.
Конечно для использования данной функции необходимы знания построения регулярных выражений,
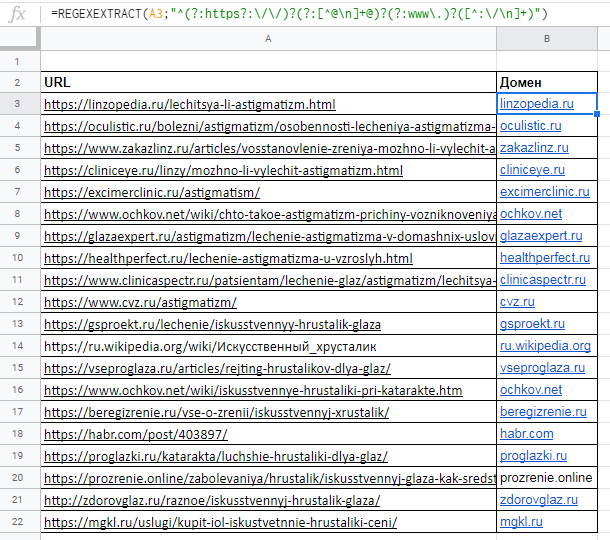
Пример использования
Нужно отделить домены от страниц. Это можно сделать с помощью выражения:
Подробнее о функциях таблиц можно почитать в справке Google.
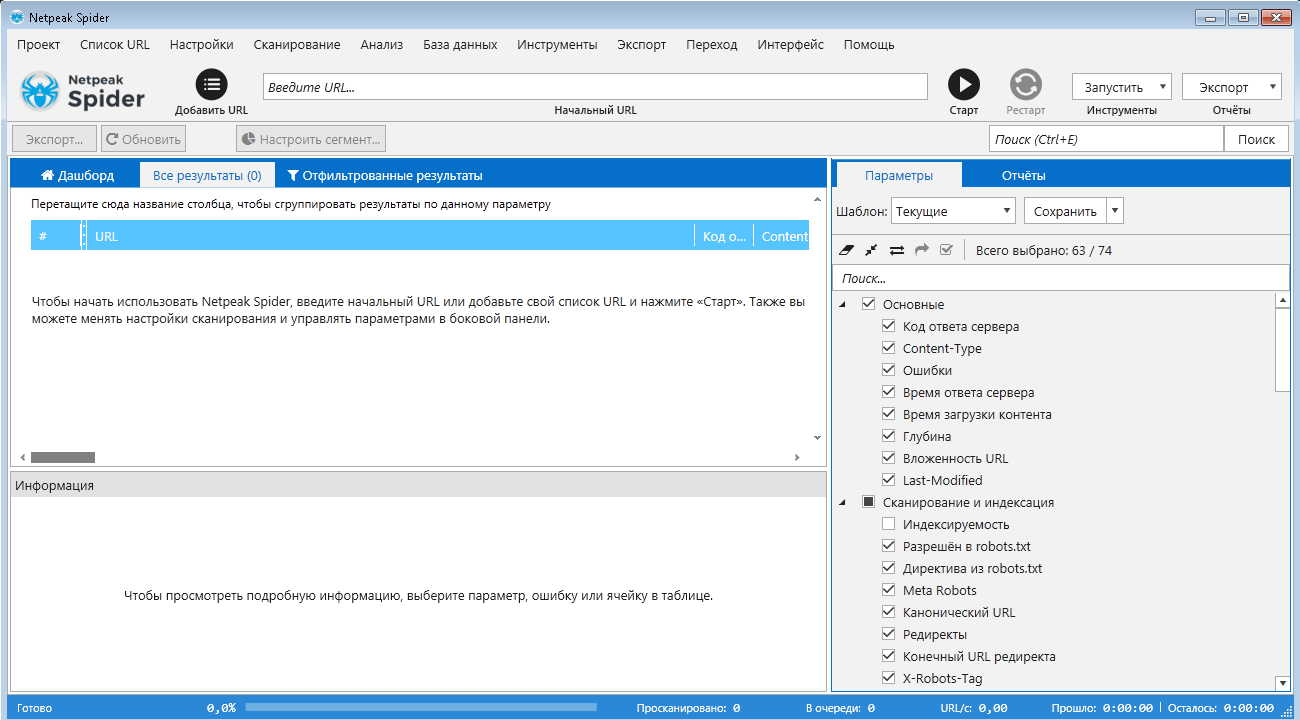
NetPeak Spider

Десктопный инструмент для регулярного SEO-аудита, быстрого поиска ошибок, системного анализа и парсинга сайтов.
Бесплатный период 14 дней, есть варианты платных лицензий на месяц и более.
Данная программа подойдет как новичкам, так и опытным SEO-специалистам. У неё интуитивно понятный интерфейс, она самостоятельно находит и кластеризует ошибки, найденные на сайте, помечает их разными цветами в зависимости от степени критичности.
Возможности Netpeak Spider:
ComparseR

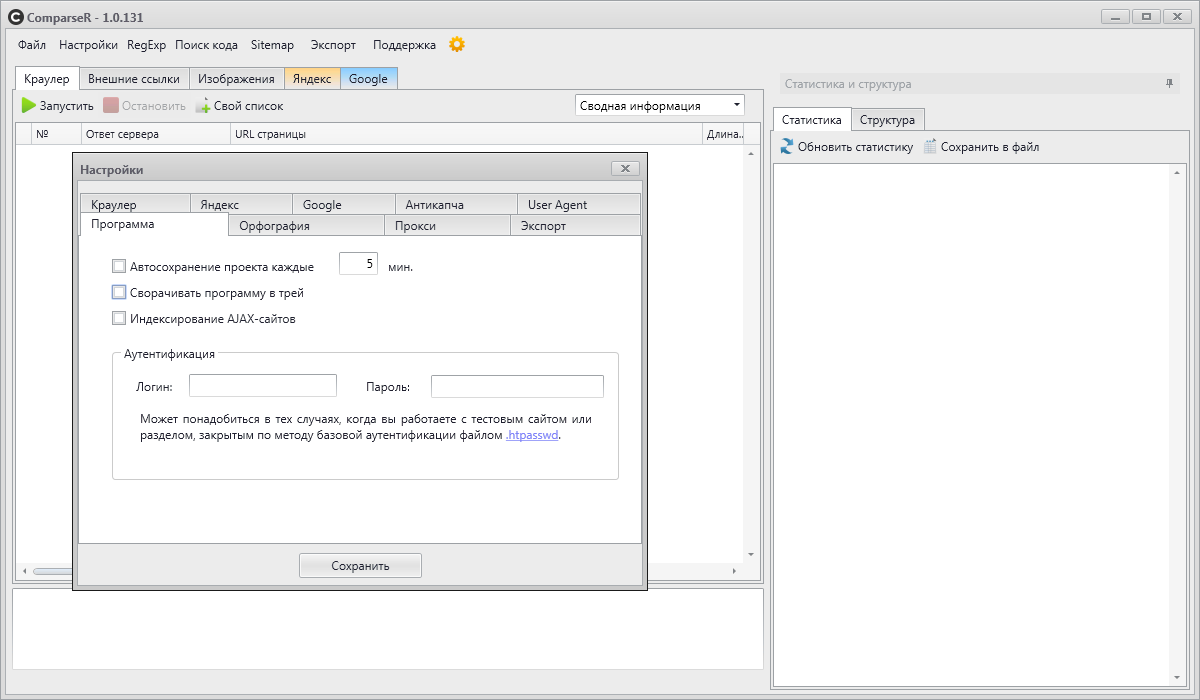
ComparseR – специализированная программа, предназначенная для глубокого изучения индексации сайта.
У демо-версии ComparseR есть 2 ограничения:
Данный парсер примечателен тем, что он заточен на сравнение того, что есть на вашем сайте и тем, что индексируется в поисковых системах.
То есть вы легко найдете страницы, которые не индексируются поисковыми системами, или наоборот, страницы-сироты (страницы, на которые нет ссылок на сайте), о которых вы даже не подозревали.
Стоит отметить, что данный парсер полностью на русском и не так требователен к мощностям компьютера, как другие аналоги.
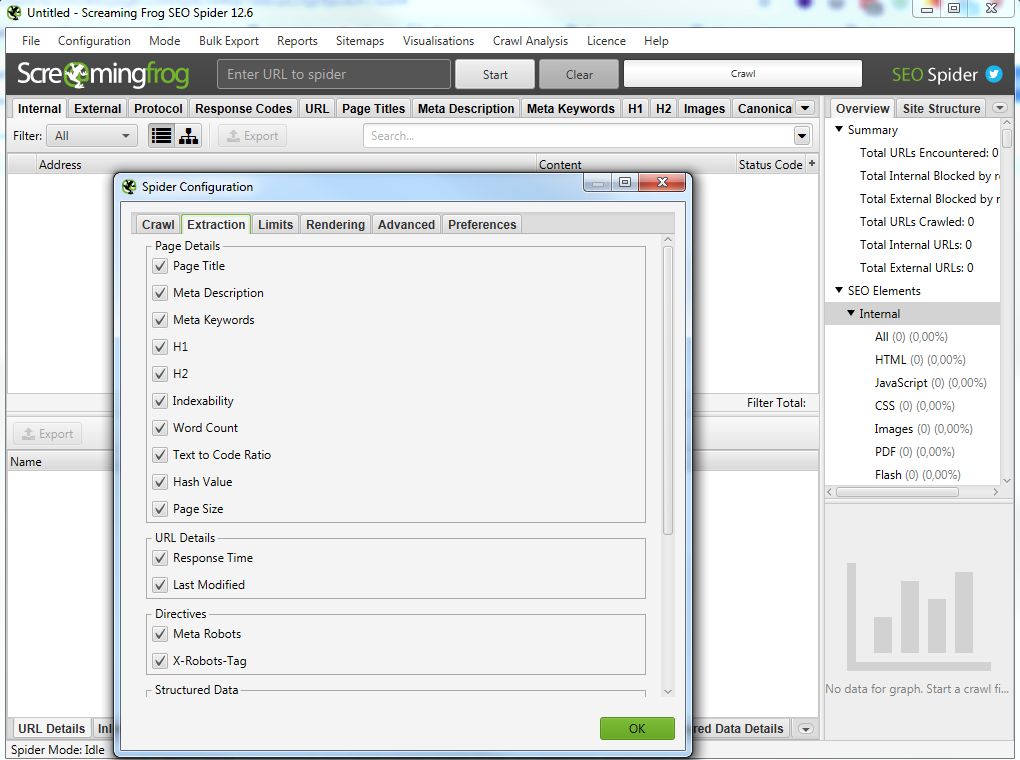
Screaming Frog SEO Spider

Особенности программы:
В бесплатной версии доступна обработка до 500 запросов.
На первый взгляд интерфейс данной программы для парсинга сайтов может показаться сложным и непонятным, особенно из-за отсутствия русского языка.
Не смотря на это, сама программа является великолепным инструментом с множеством возможностей.
Всю необходимую информацию можно узнать из подробного мануала по адресу https://www.screamingfrog.co.uk/seo-spider/user-guide/.
Примеры глубокого парсинга сайта — парсинг с конкретной целью
Пример 1 — Поиск страниц по наличию/отсутствию определенного элемента в коде страниц
Задача: — Спарсить страницы, где не выводится столбец с ценой квартиры.
Как быстро найти такие страницы на сайте с помощью Screaming Frog SEO Spider?
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, который есть на всех искомых страницах.
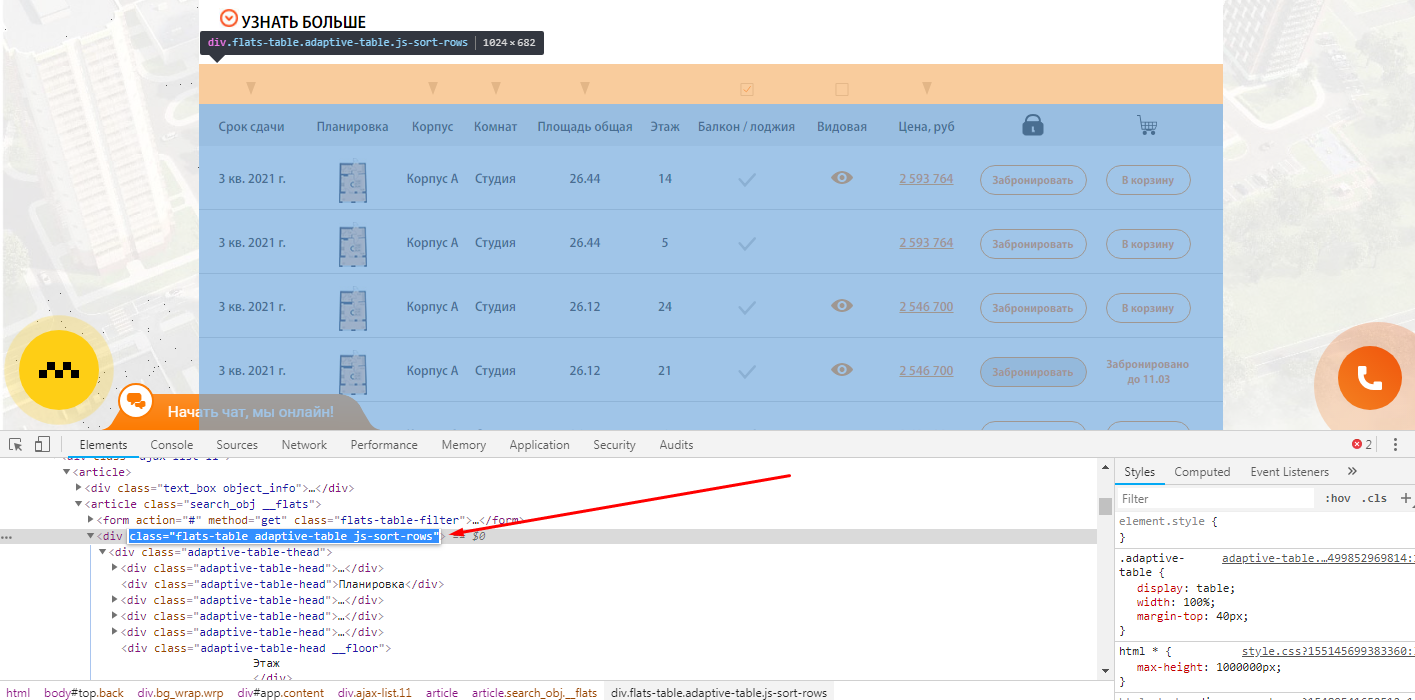
Чтобы было более понятна задача из примера, мы ищем страницы, блок которых выглядит вот так:
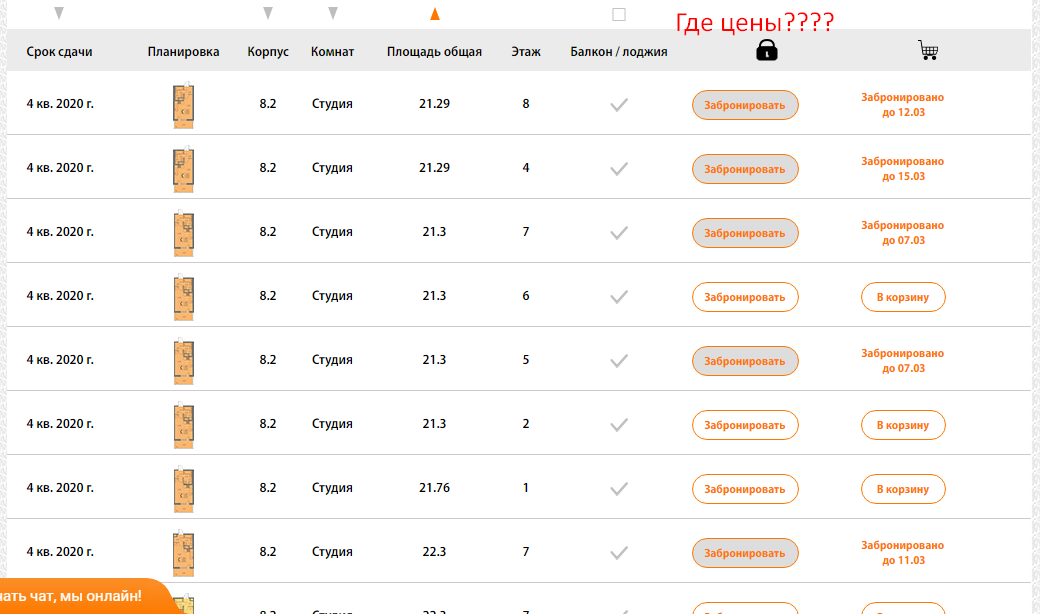
Тут же ищите элемент, который отсутствует на искомых страницах, но присутствует на нормальных страницах.
В нашем случае это столбец цен, и мы просто ищем страницы, где отсутствует столбец с таким названием (предварительно проверив, нет ли где в коде закомменченного подобного столбца)
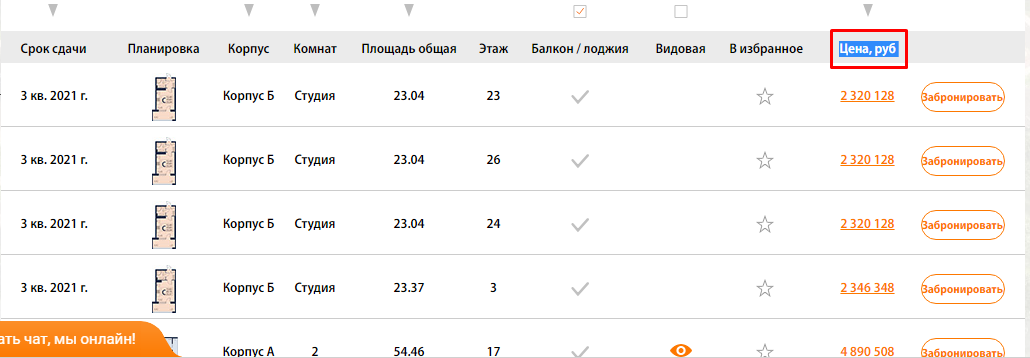
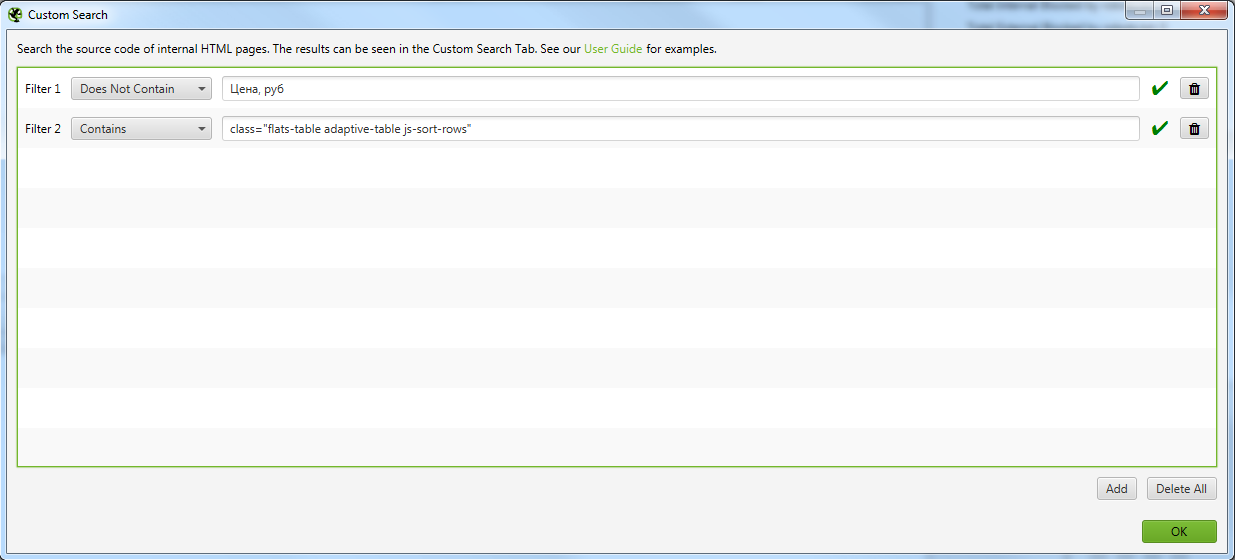
Выгружаем Custom 1 и Custom 2.
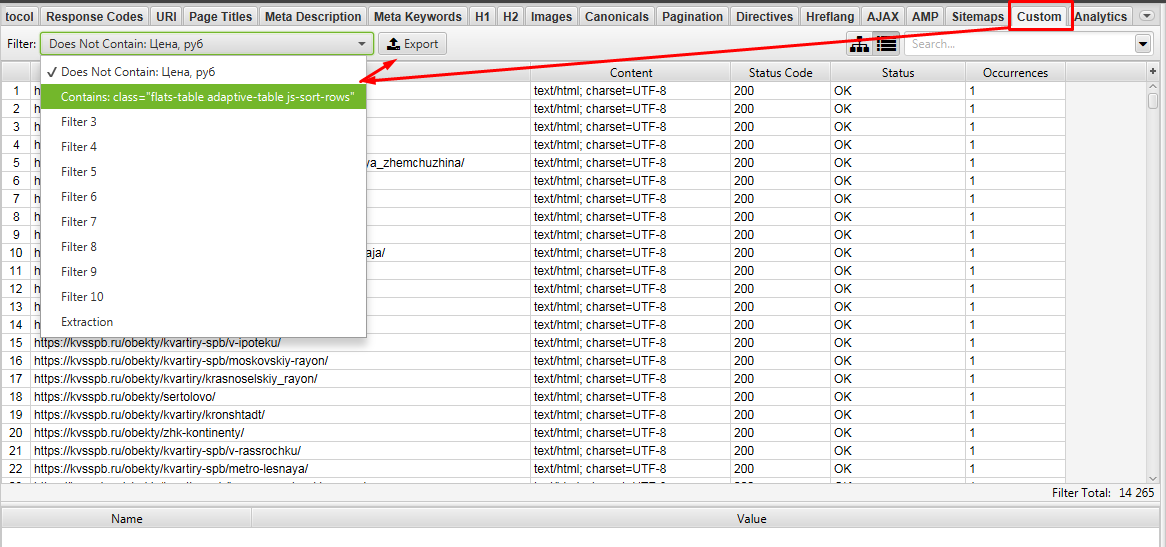
Далее в Excel ищем урлы которые совпадают между файлами Custom 1 и Custom 2. Для этого объединяем 2 файла в 1 таблицу Excel и с помощью «Повторяющихся значений» (предварительно нужно выделить проверяемый столбец).
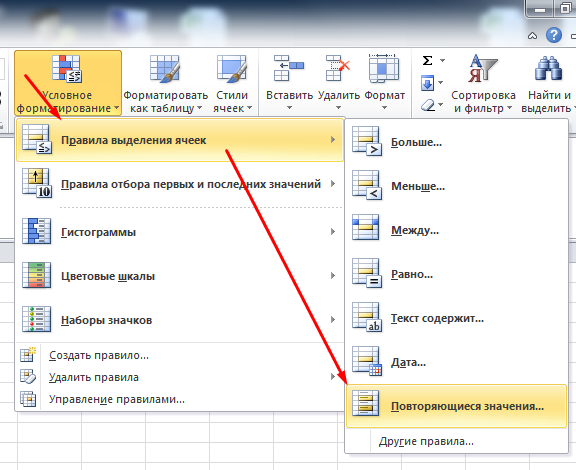
Фильтруем по красному цвету и получаем список урлов, где есть блок с выводом квартир, но нет столбца с ценами)!
Таким способом на сайте можно быстро найти и выгрузить выборку необходимых страниц для различных задач.
Пример 2 — Парсим содержимое заданного элемента на странице с помощью CSSPath
Давайте разбираться, как такое сделать
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, текст которого нам нужно выгружать.
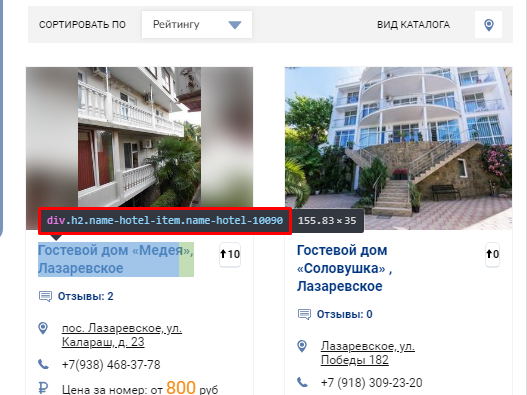
Выглядит это так
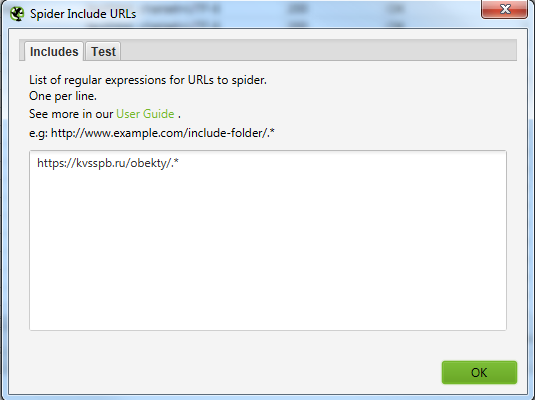
Для того, чтобы не парсить весь сайт целиком, вы можете ограничить область поиска с помощью указания конкретного раздела, который нужно парсить.
Указываем сюда разделы, в которых содержатся все нужные страницы.
Выглядит это вот так для обоих случаев.
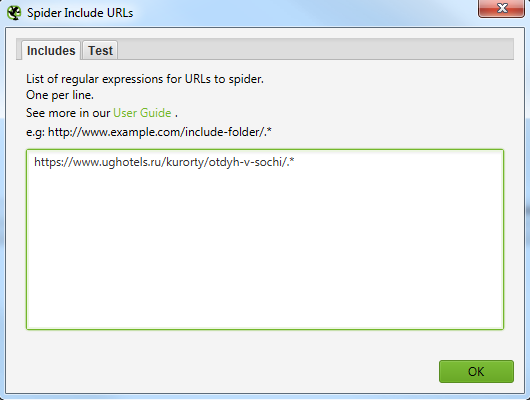
Далее парсим сайт, вбив в строку свой урл. В нашем случае это https://www.ughotels.ru/kurorty/otdyh-v-sochi.
Теперь в Excel чистим файл от пустых данных, так как не на всех страницах есть подобные блоки, поэтому данных нет.
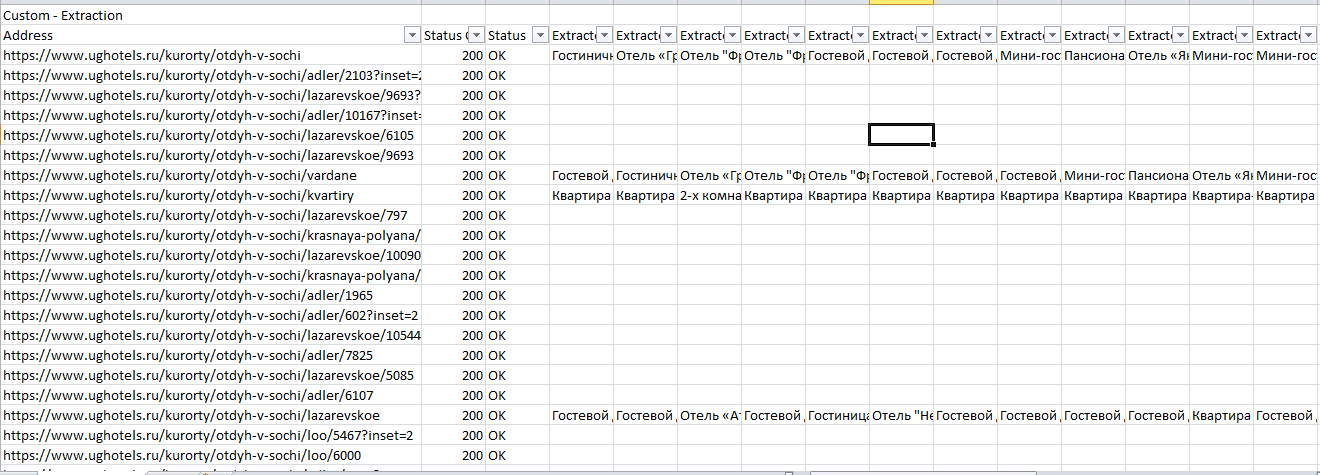
После фильтрации мы рекомендуем для удобства сделать транспонирование таблички на второй вкладке, так ее станет удобнее читать.
Для этого выделяем табличку, копируем и на новой вкладке нажимаем
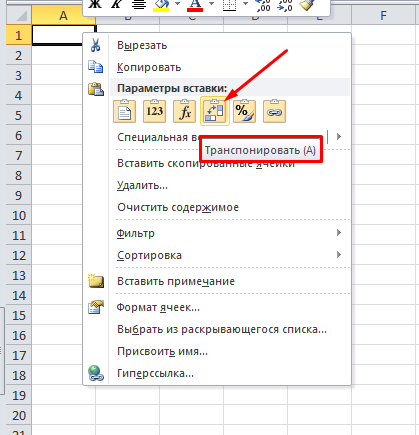
Получаем итоговый файл: 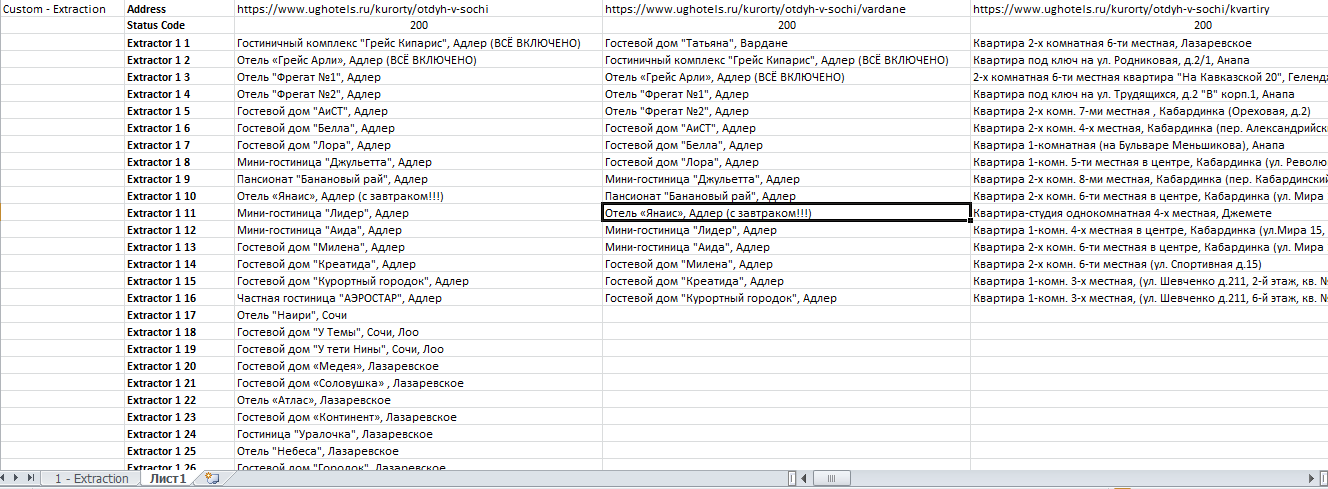
Пример 3 — Извлекаем содержимое нужных нам элементов сайта с помощью запросов XPath
Задача: Допустим, мы хотим спарсить нестандартные, необходимые только нам данные и получить на выходе таблицу с нужными нам столбцами — URL, Title, Description, h1, h2 и текст из конца страниц листингов товаров (например, https://www.funarena.ru/catalog/maty/). Таким образом, решаем сразу 2 задачи:
Сначала немного теории, знание которой позволит решить эту и многие другие задачи.
Технический парсинг сайта и сбор определенных данных со страницы с помощью запросов XPath
Как уже говорилось выше, SEO-специалисты используют технический парсинг сайта в основном для поиска “классических” тех. ошибок. У парсеров даже есть специальные алгоритмы, которые сразу помечают и классифицируют ошибки по типам, облегчая работу SEO специалиста.
Но бывают ситуации, когда с сайта необходимо извлечь содержимое конкретного класса или тега. Для этого на помощь приходит язык запросов XPath. С помощью него можно извлечь с сайта только нужную информацию, записать ее в удобный вид и затем работать с ней.
Ниже приведем примеры некоторых вариантов запросов XPath, которые могут быть вам полезны.
Данные взяты из официальной справки. Там вы сможете увидеть больше примеров.
По умолчанию парсер Screaming Frog SEO Spider собирает только h1 и h2, но если вы хотите собрать h3, то XPath запрос будет выглядеть так:
Если вы хотите спарсить только 1-й h3, то XPath запрос будет таким:
/descendant::h3[1]
Чтобы собрать первые 10 h3 на странице, XPath запрос будет:
/descendant::h3[position() >= 0 and position() Теперь вернемся к изначальной задаче
В предыдущем примере мы показали, как парсить с помощью CSSPath, принцип похож, но у него есть свои особенности.
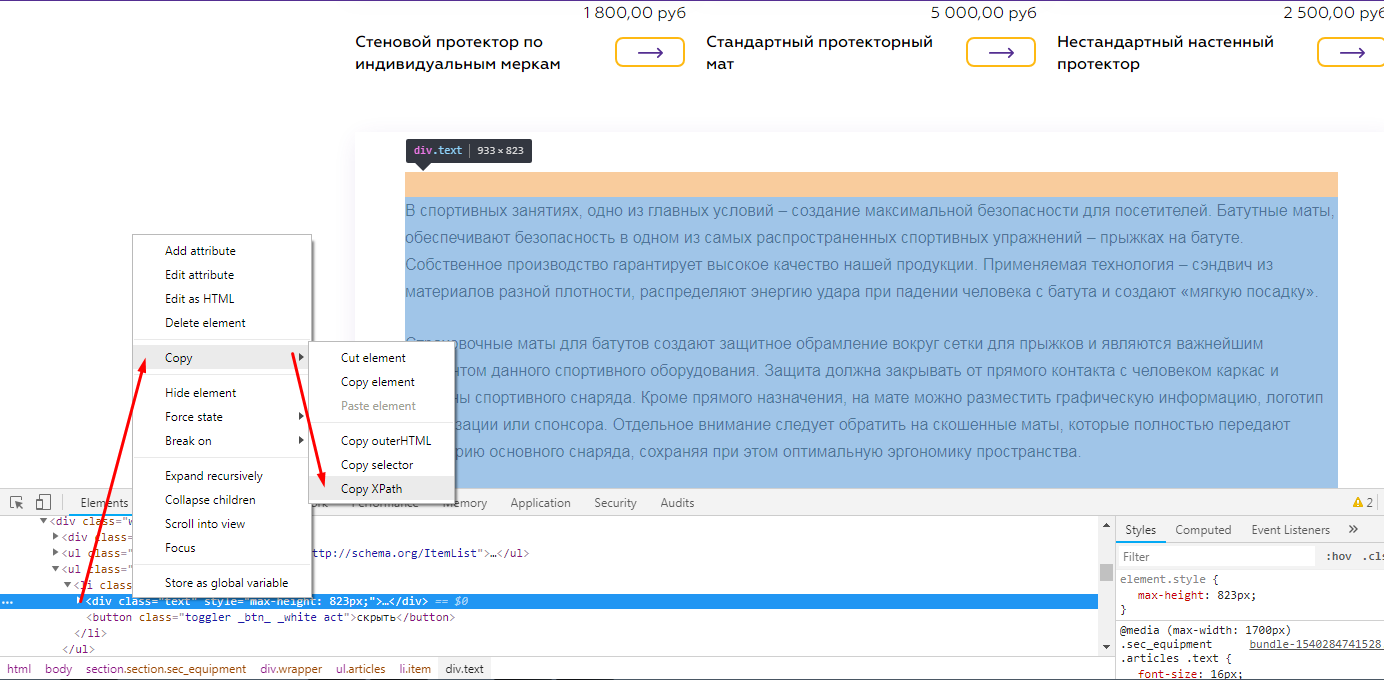
При таком копировании мы получили /html/body/section/div[2]/ul[2]/li/div
Для элементарного понимания, таким образом в коде зашифрована вложенность того места, где расположен текст. И мы получается будем проверять на страницах, есть ли текст по этой вложенности.
На скрине мы оставили вариант парсинга того же текста, но уже с помощью CSSPath, чтобы показать, что практически все можно спарсить 2-мя способами, но у Xpath все же больше возможностей.
Получаем Excel с нужными нам данными.
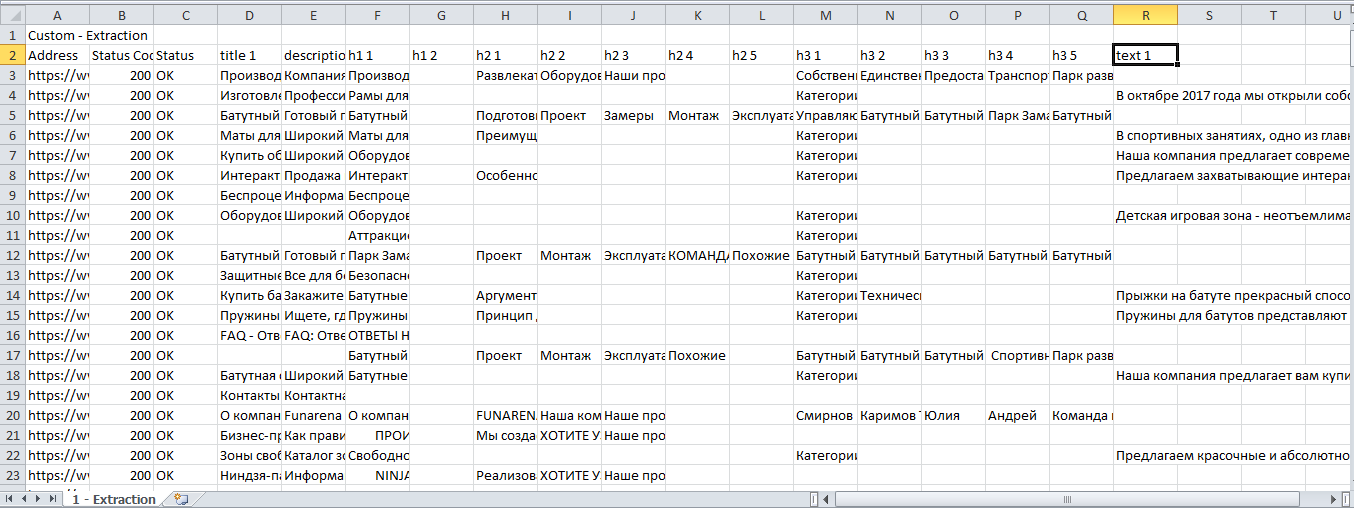
После фильтрации удобно сделать транспонирование полученных данных.

Пример 4 — Как спарсить цены и названия товаров с Интернет магазина конкурента
Задача: Спарсить товары и взять со страницы название товара и цену.

Начнем с того, что ограничим область парсинга до каталога, так как ссылки на все товары ресурса лежат в папке /catalog/. Но нас интересуют именно карточки товаров, а они лежат в папке /product/ и поэтому их тоже нужно парсить, так как информацию мы будем собирать именно с них.
https://okumashop.ru/catalog/.* ← Это страницы на которых расположены ссылки на товары.
https://okumashop.ru/product/.* ← Это страницы товаров, с которых мы будем получать информацию.
Для реализации задуманного мы воспользуемся уже известными нам методами извлечения данных с помощью CSSPath и XPath запросов.
Заходим на любую страницу товара, нажимаем F12 и через кнопку исследования элемента смотрим какой класс у названия товара.
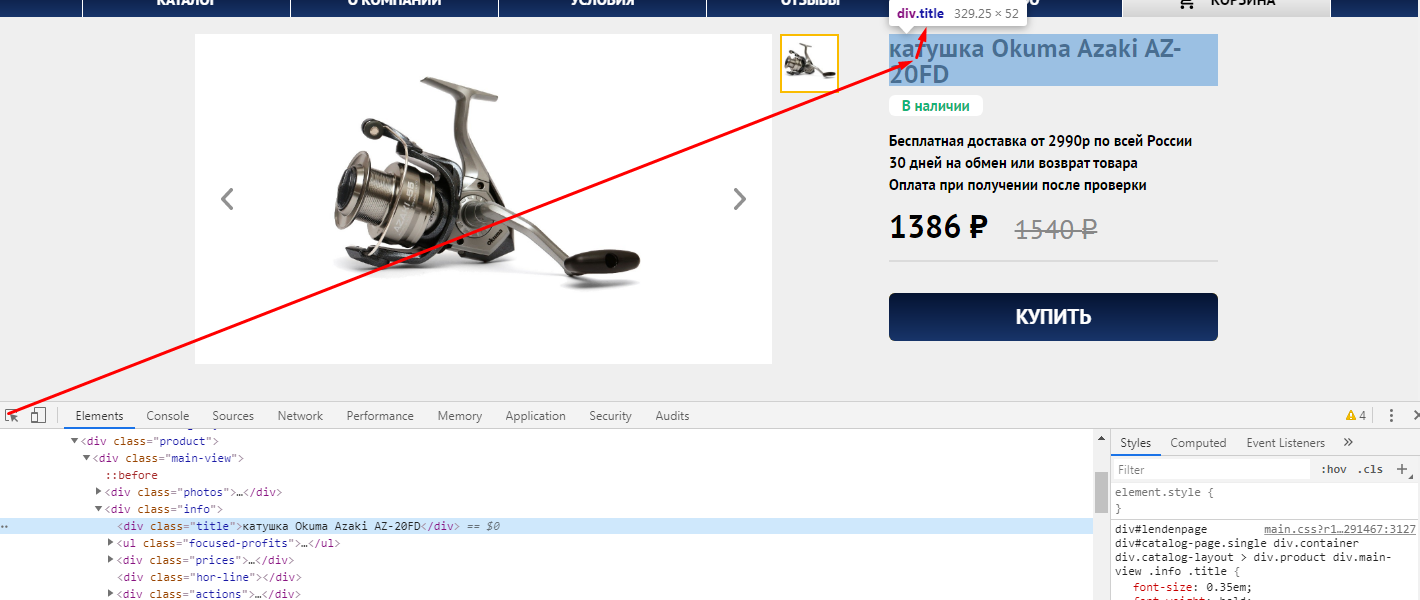
Иногда этого знания достаточно, чтобы получить нужные данные, но всегда стоит проверить, есть ли еще на сайте элементы, размеченные как
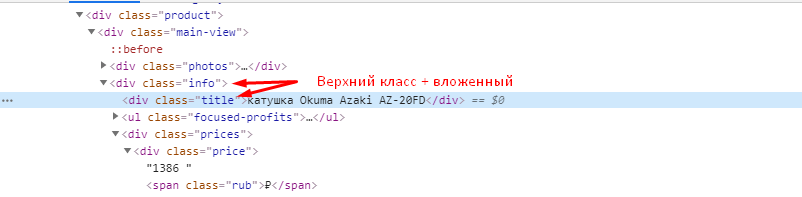
Цену можно получить, как с помощью CSSPath, так и с помощью Xpath.
Если хотим получить цену через XPath, то также через исследование элемента копируем путь XPath.
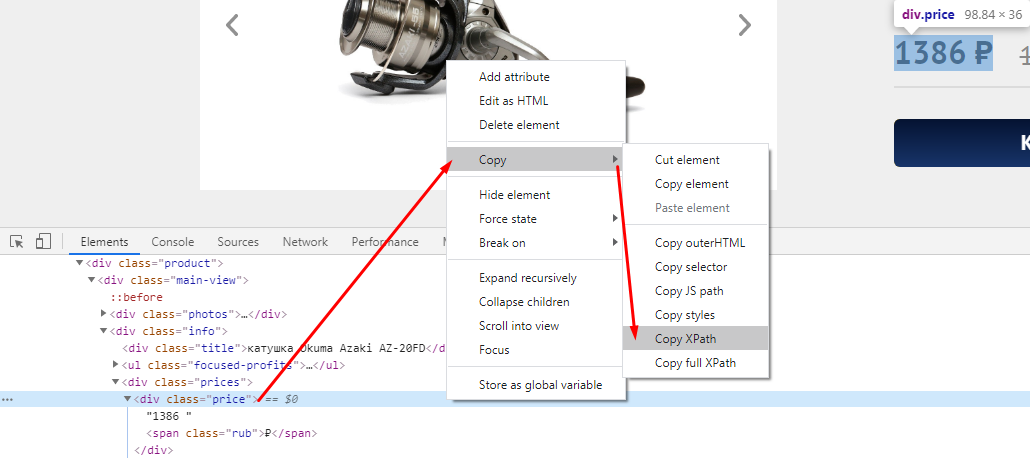
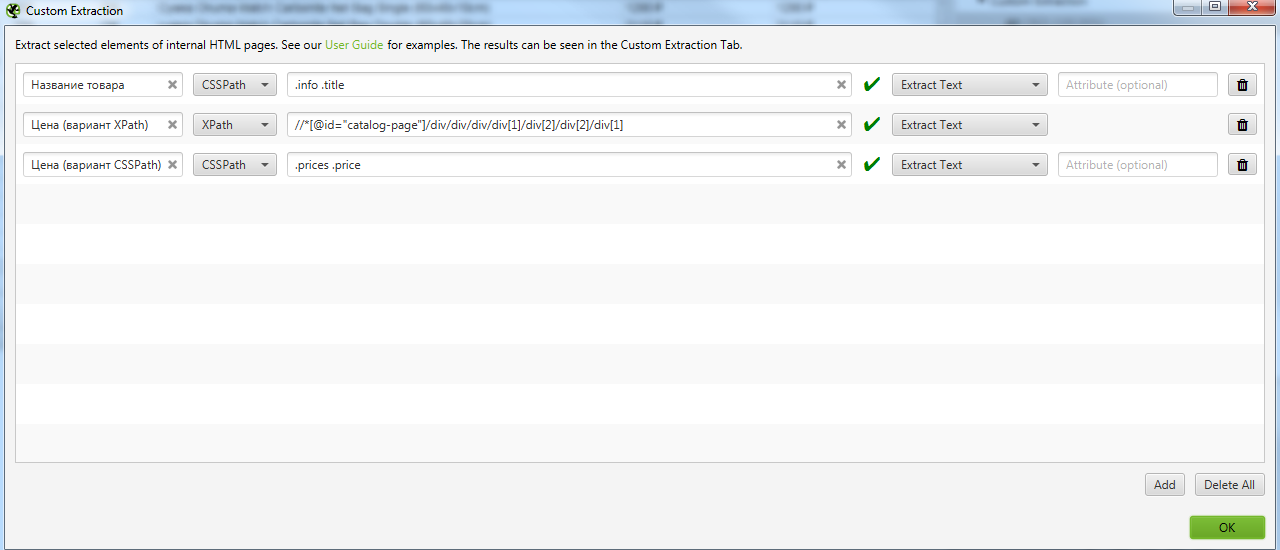
Получаем вот такой код //*[@id=»catalog-page»]/div/div/div/div[1]/div[2]/div[2]/div[1]
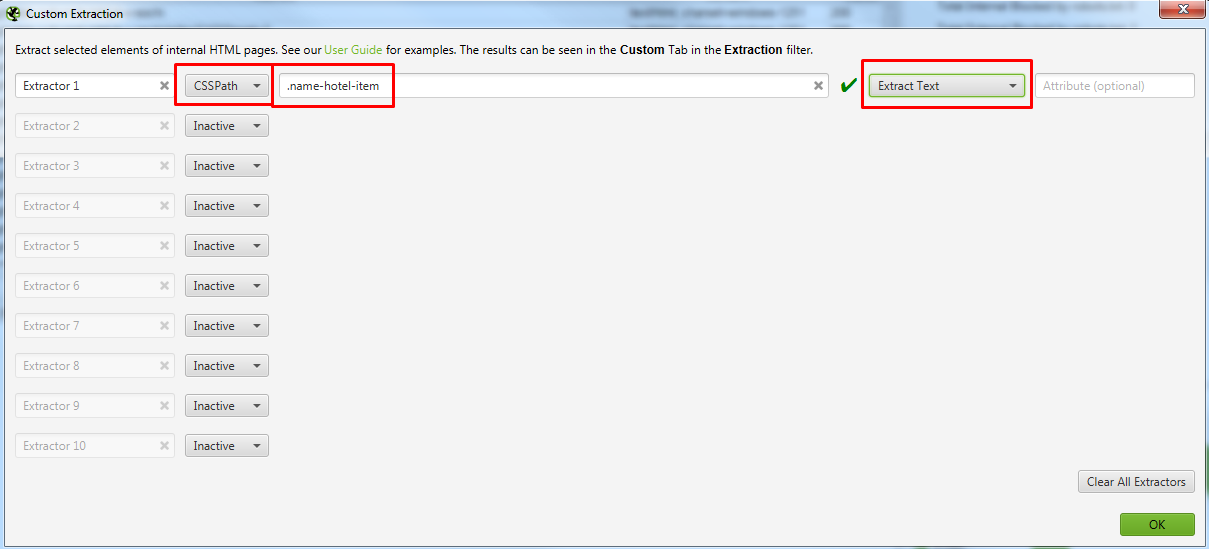
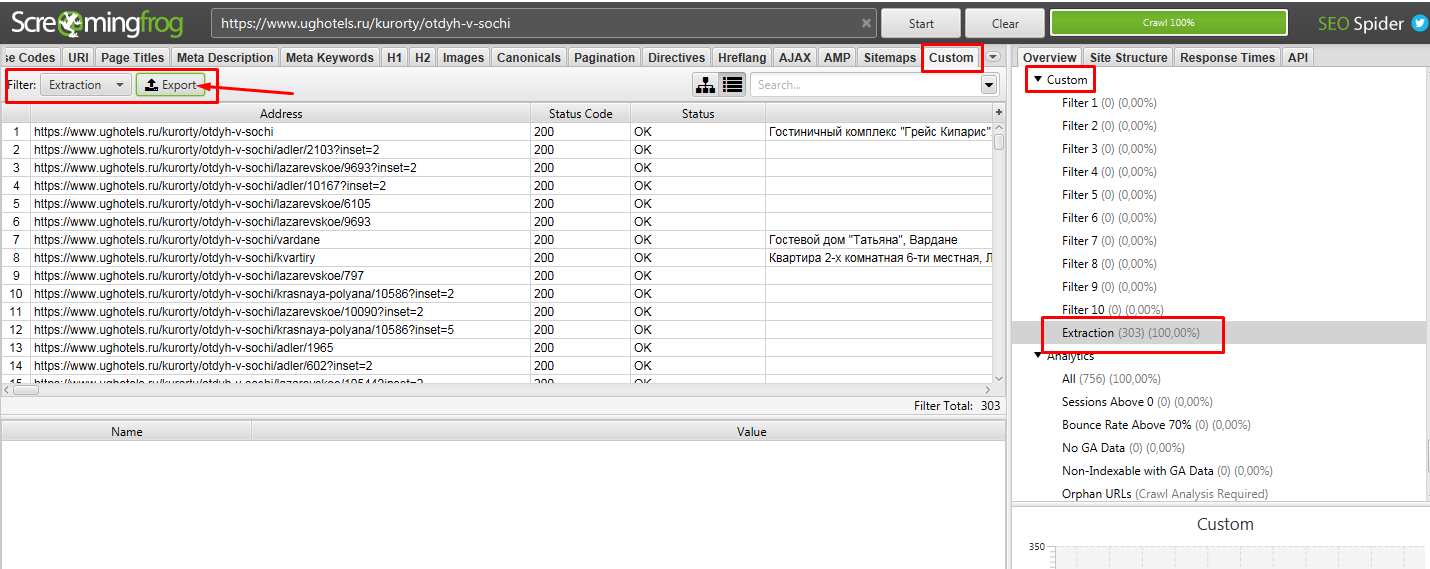
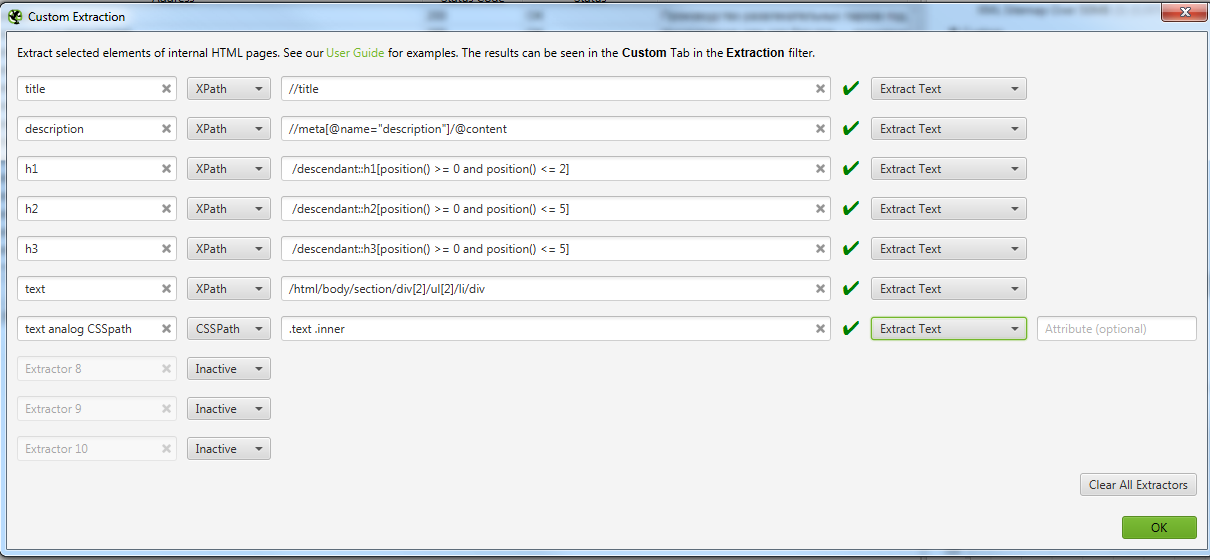
Идем в Configuration → Custom → Extraction и записываем все что мы выявили. Важно выбирать Extract Text, чтобы получать именно текст искомого элемента, а не сам код.
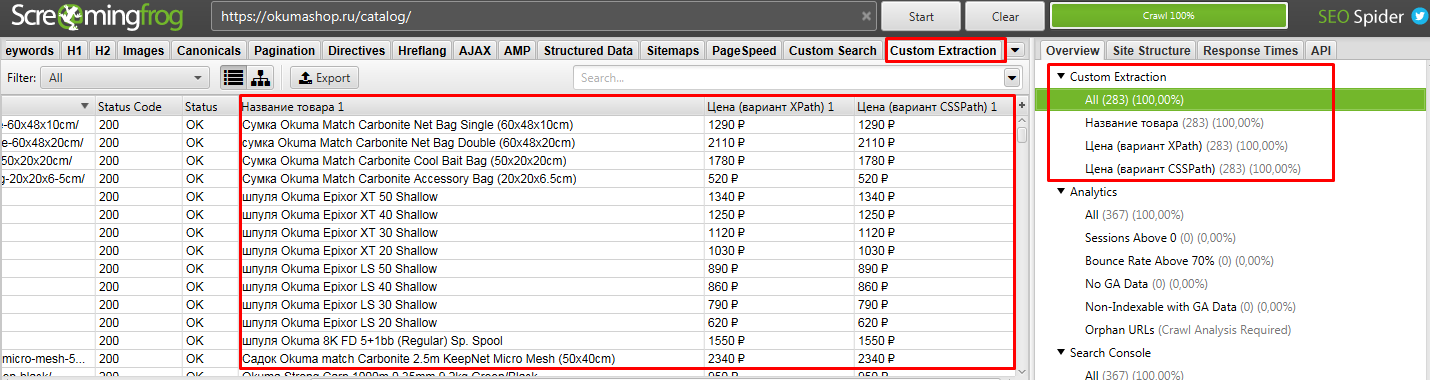
После парсим сайт. То, что мы хотели получить находится в разделе Custom Extraction. Подробнее на скрине.
Выгружаем полученные данные.
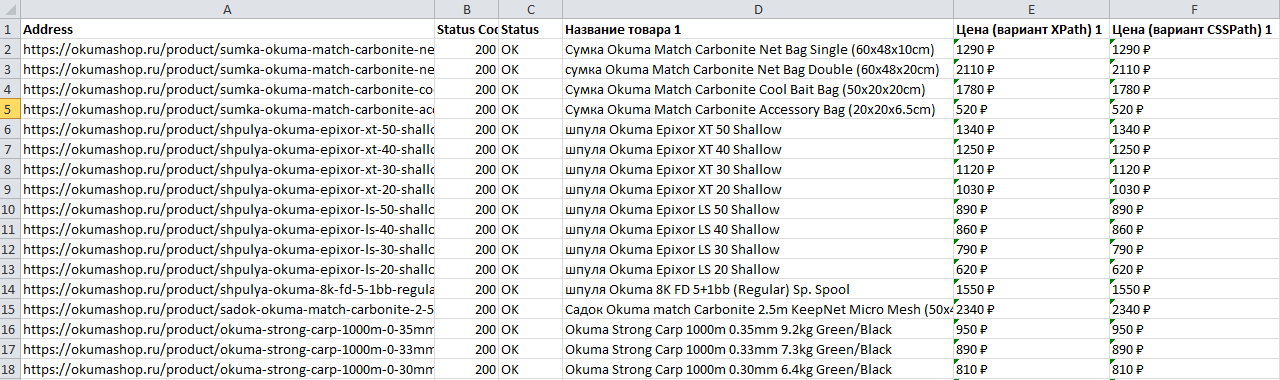
Получаем файл, где есть все необходимое, что мы искали — URL, Название и цена товара
Пример 5 — Поиск страниц-сирот на сайте (Orphan Pages)
Задача: — Поиск страниц, на которые нет ссылок на сайте, то есть им не передается внутренний вес.
Для решения задачи нам потребуется предварительно подключить к Screaming frog SEO spider Google Search Console. Для этого у вас должны быть подтверждены права на сайт через GSC.
Screaming frog SEO spider в итоге спарсит ваш сайт и сравнит найденные страницы с данными GSC. В отчете мы получим страницы, которые она не обнаружила на сайте, но нашла в Search Console.
Давайте разбираться, как такое сделать.
Подключаемся к Google Search Console. Просто нажимаете кнопку, откроется браузер, где нужно выбрать аккаунт и нажать кнопку “Разрешить”.
В окошках, указанных выше нужно найти свой сайт, который вы хотите спарсить. С GSC все просто там можно вбить домен. А вот с GA не всегда все просто, нужно знать название аккаунта клиента. Возможно потребуется вручную залезть в GA и посмотреть там, как он называется.
Выбрали, нажали ок. Все готово к чуду.
Теперь можно приступать к парсингу сайта.
Тут ничего нового. Если нужно спарсить конкретный поддомен, то в Include его добавляем и парсим как обычно.
Если по завершению парсинга у вас нет надписи “API 100%”

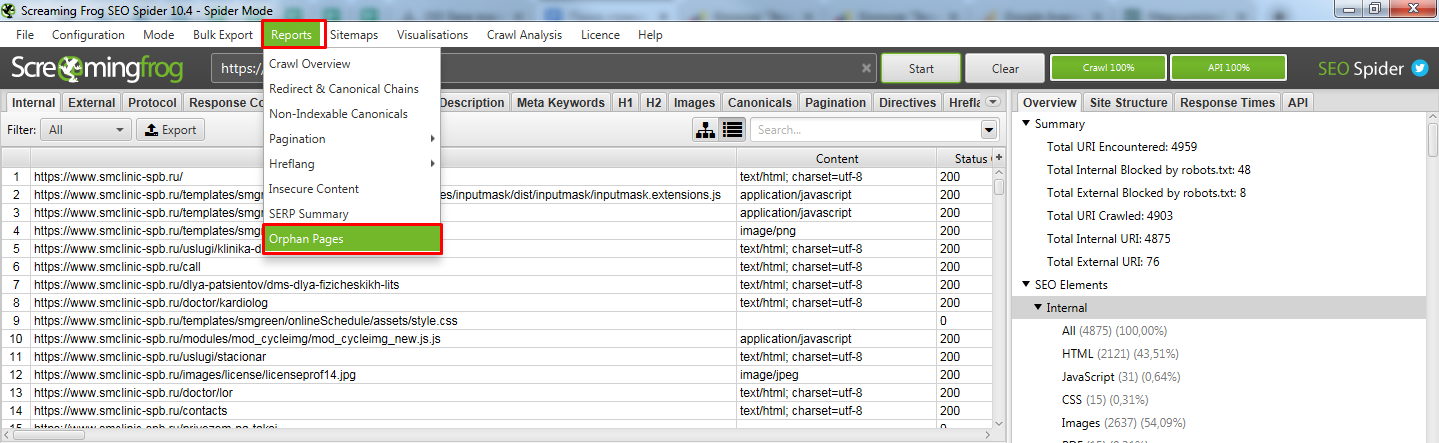
Открываем получившийся отчет. Получили список страниц, которые известны Гуглу, но Screaming frog SEO spider не обнаружил ссылок на них на самом сайте.
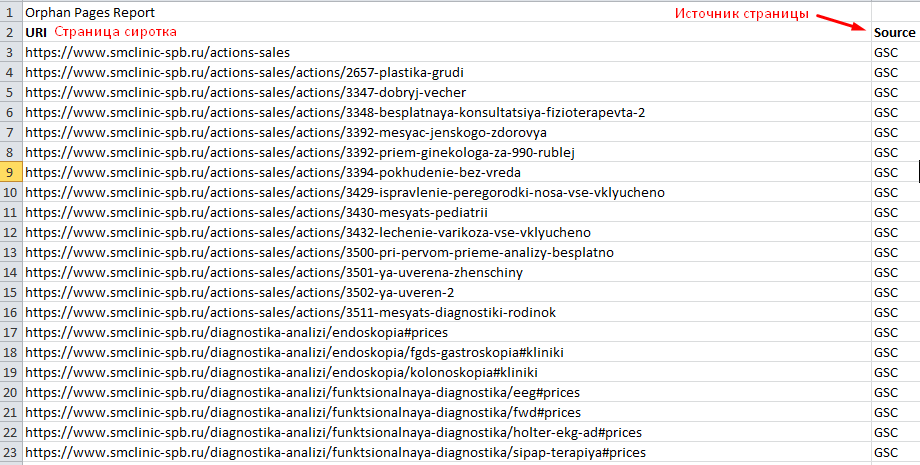
Возможно тут будет много лишних страниц (которые отдают 301 или 404 код ответа), поэтому рекомендуем прогнать весь этот список еще раз, используя метод List.
После парсинга всех найденных страниц, выгружаем список страниц, которые отдают 200 код. Таким образом вы получаете реальный список страниц-сирот с которыми нужно работать.
На такие страницы нужно разместить ссылки на сайте, если в них есть необходимость, либо удаляем страницы или настраиваем 301 редирект на существующие похожие страницы.
Вывод
Парсеры помогают очень быстро решить множество задач не только технического характера (поиска ошибок), но и массу бизнес задач, таких как, собрать структуру сайта конкурента, спарсить цены и названия товаров и и другие полезные данные.
Парсинг
![]()
Расскажем, что такое парсинг, что значит парсить данные, как правильно это делать и насколько законной является данная процедура. А также расскажем, какую информацию можно парсить на сайтах и какие есть виды парсинга.
Что такое парсинг
В переводе с английского слово парсинг означает структурирование.
Парсинг — это автоматизированный сбор и структурирование информации с сайтов при помощи программы или сервиса. Эта программа называется парсер и её задачей является сбор информации в соответствии с заданными параметрами.
 Парсинг — автоматизированный сбор и структурирование информации с сайтов
Парсинг — автоматизированный сбор и структурирование информации с сайтов
Например, при помощи парсинга сайтов можно создать описание карточек товаров онлайн-магазина. Сотрудники не тратят время на их заполнение вручную, так как все данные собирает программа.
Что значит «парсить сайт»
Парсинг сайта — это процесс сбора данных с сайтов. Вот как можно использовать такой тип парсинга:
Для чего нужен парсинг данных сайта
Большой объём данных непросто систематизировать вручную. Парсинг данных помогает:
Плюсы парсинга
По сравнению со сбором данных, который бы делался вручную, с парсерами компании могут:
Законно ли использовать парсинг
Иногда парсинг вызывает негативное отношение. Но в действительности парсинг не нарушает законодательных норм и юридическая ответственность за него не установлена.
Вот что запрещает законодательство:
Парсинг не нарушает закон, когда программы собирают данные из открытого доступа. Такую информацию можно собрать и вручную. Парсеры лишь ускоряют процесс и исключают неточности.
Незаконным может быть то, как владелец распоряжается собранной информацией — например, если бизнес полностью копирует статьи конкурентов.
Какой тип данных можно парсить с сайтов
Собирать разрешено информацию, которая находится в открытом доступе:
Как парсер собирает данные
Схематично алгоритм парсинга сайта можно представить так:
Виды парсинга
В зависимости от того, какие данные собираются, можно выделить несколько видов парсинга: