Виды моделирования. Основы скульптинга, ретопологии и развертки

В этой статье мы поговорим про скульптинг, ретопологию и развертку. Но сначала нужно определиться с целью. Что мы будем моделировать, и каким способом?
Предположим, что мы решили создавать персонажа для игры, но что если это будет окружение, архитектура или что-то еще? Сначала нужно узнать какие бывают способы моделирования и понять какой нам больше подходит.
Способы моделирования
1. Полигональное моделирование
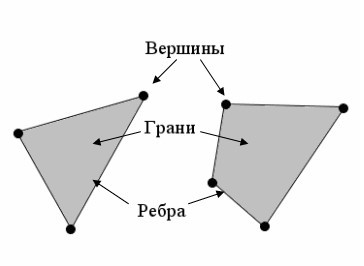
Это, наверное, самый популярный способ разработки 3D модели. Суть заключается в создании и редактировании сетки из полигонов, которые состоят из вершин и ребер. Нажимая на левую клавишу мыши мы создаем новую вершину, которая соединяется ребром.
Такой процесс моделирования можно представить как форму, например, лица, покрытую прямоугольниками с разной степенью перспективного искажения.

Говоря простым языком: «Мы создаем сетку, которая состоит из примитивных фигур (примитивов)». В результате получается многогранник. Чтобы лучше ассоциировать, можно вспомнить как в фильмах и анимации много маленьких роботов превращались в одного большого. Так же и с полигональным моделированием. Много примитивов составляют одну большую модель.
Кстати, чаще всего у полигона четыре грани, но бывает и три. Примитивы с тремя гранями используются только в определенных случаях, а вот больше четырех граней быть не может. Привязки к реальным единицам измерения нет, поэтому модель получается неточной. Соответственно, такой способ не подходит для моделирования каких-то деталей или архитектурных проектов, где важен каждый миллиметр.
Вы просто передвигаете вершину, ребро или весь полигон, ориентируясь на внешний вид. Полигональное моделирование хорошо подойдет, если вы моделируете художественную вещь, и вам не важны точные размеры. Это может быть персонаж, локация уровня игры или животное.
2. NURBS моделирование

Основное отличие этого способа от полигонального моделирования в плавности. NURBS модель состоит не из полигонов, а из кривых (сплайнов), однако при визуализации все равно преобразуется в полигоны, хотя внутри системы моделирования остается в кривых. Используется для создания плавных органических форм и моделей.
Допустим, нужно представить сложную трехмерную поверхность природного происхождения. Ее можно описывать вершинами и разбивать на примитивы, но на это уйдет много времени, а изменять кривизну поверхности в полигонах будет просто не удобно. В таких случаях как раз и применим способ NURBS моделирования.
3. Точное моделирование в Сапрах
В этом способе модель задается математическими формулами, поэтому поверхность модели будет абсолютно гладкая при любом приближении, а настроить ее можно с точностью до миллиметра.
Используется, когда важна точность, а не художественная выразительность. Чисто теоретически, таким способом можно создать персонажа, но но это займет огромное количество времени и усилий, в отличие от полигонального моделирования и скульптинга.
Про полигоны

Возвращаемся к полигона. Почему в каких-то моделях их больше, а в каких-то меньше?
Дело в том, что модели делятся по количеству полигонов:
В играх на ПК и консоли чаще всего используют mid-poly, иногда hi-poly (в AAA проектах), а в мобильных играх low poly.
Скульптинг

Приступаем к части моделирования под названием «Скульптинг». Это первый 3D этап в создании персонаж. В нем персонаж лепится как из глины, отсюда и название. На этом этапе можно окунуться в творчество и лепить не задумываясь о полигонах. А их будет много. Не волнуйтесь, позже все это дело мы упростим. Кстати, для обучения скульптингу хорошо бы приобрести графический планшет.
И так, плавно переходим к основной теме статьи. Но я ничего же не сказал про программы. Предлагаю взять Zbrush для скульптинга и 3D Coat для ретопологии и развертки. Первым делом нужно запустить Zbrush. Мы попадаем в основной экран программы. Сначала нам нужно создать сферу.
Во вкладке Tool, которая находится в правой части экрана, выбираем пункт «Sphere3D». Вытягиваем сферу в рабочей области нажатием лкм.
Для перемещения используем горячие клавиши:
Появляется панель с кистями. Для редактирования сферы нажимаем «Edit».
Чтобы не получать такое сообщение нужно нажать «Make PolyMesh 3D » в панели Tool.
Теперь можно скульптить. Осталось только включить симметрию на клавишу «X». При нажатии на alt кисть начинает работать в обратную сторону. Если кисть выдавливала, то наоборот будет вдавливать. Для ушей, глаз, носа лучше всего создавать отдельные сферы и скульптить их отдельно. Со временем сетка будет меняться и понадобится пересчитать полигоны. Для этого во вкладке Geometry нужно нажать DynaMesh.
Если работать только с одной сферой, то вся детализация сойдет на нет при пересчете полигонов. Так что лучше делать это отдельными объектами, а под конец работы объединить.
Если нет идей для скульптинга, можно зайти на artstation.com и найти понравившуюся работу. Можно найти концепт-арты, добавить Zbrush и использовать как референс для тренировки.
В процессе работы над моделью может понадобиться инструмент «маска». Применить его можно нажав на ctrl. Маска — это область на которую не реагирует кисть. Таким образом можно лепить много чего интересного.
Под конец работы над моделью получится примерно 1 — 3 миллиона полигонов. Такую модель будет сложно открыть в другой программе, поэтому нужно сократить количество полигонов. Для этого во вкладке Zplugin выберем пункт «Decimation Master» и нажмем на Pre-process All. Zbrush запустит процесс и сократит количество полигонов.
Готовую модель можно вывести в формате obj. Его кушают практически все редакторы. Сохранить можно нажав на «Export» в панели Tool.
Ретопология
В нашей модели еще достаточно много полигонов. Чтобы упростить нужно как бы покрыть модель полигонами вручную, сохраняя форму. Это и есть процесс ретопологии. Чтобы приступить, нужно перейти во вкладку Retopology. Тут нам нужно фактически вручную рисовать полигоны. Вот пример того, как они должны располагаться.

Вокруг глаз и рта полигоны выстраиваем кругом. На месте сгибов добавляем больше полигонов, а на неподвижных частях полигоны могут быть большие и в малом количестве, например, на затылке и лбе.
Развертка
Развертка или UV mapping очень важный процесс в разработке модели. На этом этапе мы уже подготавливаем модель к текстурированию.В чем суть? Представьте картонную коробку, которую разложили на плоскости. Коробку разобрали и теперь она в виде одного листа картона. Так же и с нашей моделью, мы разложили ее в 2D пространстве.

Нажимаем на вкладку uv mapping. 3D Coat показывает развертку модели на данный момент. Синим и красным цветом отмечены артефакты. Чтобы текстура без проблем ложилась на модель нужно, чтобы во вкладке UV Preview был только серый цвет. Как это сделать? На shift + лкм нужно удалить ненужные швы так, чтобы модель разделилась на части. UV развертка нужна для удобства текстурирования и экономии ресурсов.
После того, как на модели не останется артефактов нужно нажать упаковать UV, а потом применить UV раскладку. Поздравляю, модель окончательно готова к анимации и текстурированию.
Моделирование данных: зачем нужно и как реализовать
Моделирование данных ощутимо упрощает взаимодействие между разработчиками, аналитиками и маркетологами, как и сам процесс создания отчетов. Поэтому я перевела статью IBM Cloud Education о ценности моделирования и от себя добавила инфо о способах трансформации данных для моделирования.
Моделирование данных
Узнайте, как моделирование данных использует абстракцию для представления и лучшего понимания природы данных в информационной системе предприятия.
Что такое моделирование данных
Моделирование данных — это создание визуального представления о всей информационной системе либо ее части. Цель в том, чтобы проиллюстрировать типы данных, которые используются и хранятся в системе, отношения между этими типами данных, способы группировки и организации данных, их форматы и атрибуты.
Модели данных строятся на основе бизнес-потребностей. Правила и требования к модели данных определяются заранее на основе обратной связи с бизнесом, поэтому их можно включить в разработку новой системы или адаптировать к существующей.
Данные можно моделировать на различных уровнях абстракции. Процесс начинается со сбора бизнес-требований от заинтересованных сторон и конечных пользователей. Эти бизнес-правила затем преобразуются в структуры данных. Модель данных можно сравнить с дорожной картой, планом архитектора или любой формальной схемой, которая способствует более глубокому пониманию того, что разрабатывается.
Моделирование данных использует стандартизированные схемы и формальные методы. Это обеспечивает последовательный и предсказуемый способ управления данными в организации или за ее пределами.
В идеале модели данных — это живые документы, которые развиваются вместе с потребностями бизнеса. Они играют важную роль в поддержке бизнес-процессов и планировании ИТ-архитектуры и стратегии. Моделями данных можно делиться с поставщиками, партнерами и коллегами.
Преимущества моделирования данных
Моделирование упрощает просмотр и понимание взаимосвязей между данными для разработчиков, архитекторов данных, бизнес-аналитиков и других заинтересованных лиц. Кроме того, моделирование данных помогает:
Уменьшить количество ошибок при разработке программного обеспечения и баз данных.
Унифицировать документацию на предприятии.
Повысить производительность приложений и баз данных.
Упростить отображение данных по всей организации.
Улучшить взаимодействие между разработчиками и командами бизнес-аналитики.
Упростить и ускорить процесс проектирования базы данных на концептуальном, логическом и физическом уровнях.
Типы моделей данных
Разработка баз данных и информационных систем начинается с высокого уровня абстракции и с каждым шагом становится все точнее и конкретнее. В зависимости от степени абстракции модели данных можно разделить на три категории. Процесс начинается с концептуальной модели, переходит к логической модели и завершается физической моделью.
Концептуальные модели данных. Также они называются моделями предметной области и описывают общую картину: что будет содержать система, как она будет организована и какие бизнес-правила будут задействованы. Концептуальные модели обычно создаются в процессе сбора исходных требований к проекту. Как правило, они включают классы сущностей (вещи, которые бизнесу важно представить в модели данных), их характеристики и ограничения, отношения между сущностями, требования к безопасности и целостности данных. Любые обозначения обычно просты.
Логические модели данных уже не так абстрактны и предоставляют более подробную информацию о концепциях и взаимосвязях в рассматриваемой области. Они содержат атрибуты данных и показывают отношения между сущностями. Логические модели данных не определяют никаких технических требований к системе. Этот этап часто пропускается в agile или DevOps-практиках. Логические модели данных могут быть полезны для проектов, ориентированных на данные по своей природе. Например, для проектирования хранилища данных или разработки системы отчетности.
Физические модели данных представляют схему того, как данные будут храниться в базе. По сути, это наименее абстрактные из всех моделей. Они предлагают окончательный дизайн, который может быть реализован как реляционная база данных, включающая ассоциативные таблицы, которые иллюстрируют отношения между сущностями, а также первичные и внешние ключи для связи данных.
Процесс моделирования данных
Моделирование данных начинается с договоренности о том, какие символы используются для представления данных, как размещаются модели и как передаются бизнес-требования. Это формализованный рабочий процесс, включающий ряд задач, которые должны выполняться итеративно. Сам процесс обычно выглядят так:
Определите сущности. На этом этапе идентифицируем объекты, события или концепции, представленные в наборе данных, который необходимо смоделировать. Каждая сущность должна быть целостной и логически отделенной от всех остальных.
Определите ключевые свойства каждой сущности. Каждый тип сущности можно отличить от всех остальных, поскольку он имеет одно или несколько уникальных свойств, называемых атрибутами. Например, сущность «клиент» может обладать такими атрибутами, как имя, фамилия, номер телефона и т.д. Сущность «адрес» может включать название и номер улицы, город, страну и почтовый индекс.
Определите связи между сущностями. Самый ранний черновик модели данных будет определять характер отношений, которые каждая сущность имеет с другими. В приведенном выше примере каждый клиент «живет по» адресу. Если бы эта модель была расширена за счет включения сущности «заказы», каждый заказ также был бы отправлен на адрес. Эти отношения обычно документируются с помощью унифицированного языка моделирования (UML).
Полностью сопоставьте атрибуты с сущностями. Это гарантирует, что модель отражает то, как бизнес будет использовать данные. Широко используются несколько формальных шаблонов (паттернов) моделирования данных. Объектно-ориентированные разработчики часто применяют шаблоны для анализа или шаблоны проектирования, в то время как заинтересованные стороны из других областей бизнеса могут обратиться к другим паттернам.
Назначьте ключи по мере необходимости и определите степень нормализации. Нормализация — это метод организации моделей данных, в которых числовые идентификаторы (ключи) назначаются группам данных для установления связей между ними без повторения данных. Например, если каждому клиенту назначен ключ, этот ключ можно связать как с его адресом, так и с историей заказов, без необходимости повторять эту информацию в таблице с именами клиентов. Нормализация помогает уменьшить объем дискового пространства, необходимого для базы данных, но может сказываться на производительности запросов.
Завершите и проверьте модель данных. Моделирование данных — это итеративный процесс, который следует повторять и совершенствовать под потребности бизнеса.
Типы моделирования данных
Моделирование данных развивалось вместе с системами управления базами данных (СУБД), при этом типы моделей усложнялись по мере роста потребностей предприятий в хранении данных.
Иерархические модели данных представляют отношения «один ко многим» в древовидном формате. В модели этого типа каждая запись имеет единственный корень или родительский элемент, который сопоставляется с одной или несколькими дочерними таблицами. Эта модель была реализована в IBM Information Management System (IMS) в 1966 году и быстро нашла широкое применение, особенно в банковской сфере. Хотя этот подход менее эффективен, чем недавно разработанные модели баз данных, он все еще используется в системах расширяемого языка разметки (XML) и географических информационных системах (ГИС).
Реляционные модели данных были предложены исследователем IBM Э. Ф. Коддом в 1970 году. Они до сих пор встречаются во многих реляционных базах данных, обычно используемых в корпоративных вычислениях. Реляционное моделирование не требует детального понимания физических свойств используемого хранилища данных. В нем сегменты данных объединяются с помощью таблиц, что упрощает базу данных.
Реляционные базы данных часто используют язык структурированных запросов (SQL) для управления данными. Эти базы подходят для поддержания целостности данных и минимизации избыточности. Они часто используются в кассовых системах, а также для других типов обработки транзакций.
В ER-моделях данных используют диаграммы для представления взаимосвязей между сущностями в базе данных. ER-модель представляет собой формальную конструкцию, которая не предписывает никаких графических средств её визуализации. В качестве стандартной графической нотации, с помощью которой можно визуализировать ER-модель, была предложена диаграмма «сущность-связь» (Entity-Relationship diagram). Однако для визуализации ER-моделей могут использоваться и другие графические нотации, либо визуализация может вообще не применяться (например, только текстовое описание).
Объектно-ориентированные модели данных получили распространение как объектно-ориентированное программирование и стали популярными в середине 1990-х годов. Вовлеченные «объекты» — это абстракции сущностей реального мира. Объекты сгруппированы в иерархии классов и имеют связанные черты. Объектно-ориентированные базы данных могут включать таблицы, но могут также поддерживать более сложные связи. Этот подход часто используется в мультимедийных и гипертекстовых базах данных.
Размерные модели данных разработал Ральф Кимбалл для быстрого поиска данных в хранилище. Реляционные и ER-модели делают упор на эффективное хранение и уменьшают избыточность данных, а размерные модели упорядочивает данные таким образом, чтобы легче было извлекать информацию и создавать отчеты. Это моделирование обычно используется в системах OLAP.
Две популярные размерные модели данных — это схемы «звезда» и «снежинка». В схеме «звезда» данные организованы в факты (измеримые элементы) и измерения (справочная информация), где каждый факт окружен связанными с ним измерениями в виде звездочки. Схема «снежинка» напоминает схему «звезда», но включает дополнительные слои связанных измерений, что усложняет схему ветвления.
Инструменты для моделирования данных
Сегодня широко используются многочисленные коммерческие и CASE-решения с открытым исходным кодом, в том числе различные инструменты моделирования данных, построения диаграмм и визуализации. Вот несколько примеров:
erwin Data Modeler — это инструмент моделирования данных, основанный на языке IDEF1X, который теперь поддерживает и другие нотации, включая нотацию для размерного моделирования.
Enterprise Architect — это инструмент визуального моделирования и проектирования, который поддерживает моделирование корпоративных информационных систем и архитектур, программных приложений и баз данных. Он основан на объектно-ориентированных языках и стандартах.
ER/Studio — это программа для проектирования баз данных, совместимая с некоторыми из самых популярных СУБД. Она поддерживает как реляционное, так и размерное моделирование данных.
Бесплатные инструменты моделирования данных включают решения с открытым исходным кодом, такие как Open ModelSphere.
Для того, чтобы преобразовать данные в структуру, которая соответствует требованиям модели, можно использовать встроенный механизм регулярных запросов, которые выполняются в Google BigQuery, Scheduled Queries и AppScript. Их легко можно освоить, потому что это привычный SQL, но проводить отладку в Scheduled Queries практически нереально. Особенно, если это какой-то сложный запрос или каскад запросов.
Есть специализированные инструменты для управления SQL-запросами, например, dbt и Dataform.
dbt (data build tool) — это фреймворк с открытым исходным кодом для выполнения, тестирования и документирования SQL-запросов, который позволяет привнести элемент программной инженерии в процесс анализа данных. Он помогает оптимизировать работу с SQL-запросами: использовать макросы и шаблоны JINJA, чтобы не повторять в сотый раз одни и те же фрагменты кода.
Главная проблема, которую решают специализированные инструменты — это уменьшение времени, необходимого на поддержку и обновление. Это достигается за счет удобства отладки.
Зачем Мордашов продает Троценко угольный бизнес
«Северсталь» Алексея Мордашова 2 декабря сообщила, что подписала с компанией «Русская энергия» Романа Троценко обязывающее соглашение о продаже «Воркутаугля», на базе которого консолидированы угольные активы металлургической группы. Сумма сделки составляет 15 млрд руб., закрытие ожидается в I квартале 2022 г. Сторонам еще предстоит получить разрешение ФАС и выполнить ряд других условий, которые в релизе не называются.
По оценке «Северстали», после продажи «Воркутаугля» выбросы парниковых газов компании сократятся на 14,3%. Средства от продажи актива «Северсталь» планирует направить, в том числе, на достижение целей по декарбонизации, указывается в сообщении компании.
В то же время коксующийся уголь «в среднесрочной перспективе, останется неотъемлемым компонентом металлургического производства», подчеркивают в «Северстали». Поэтому сделка с Троценко также предполагает заключение долгосрочного контракта с «Русской энергией» на покупку угля.
Гендиректор и совладелец «Русской энергии» Андрей Тясто, слова которого приводятся в релизе, отметил, что компания «верит в развитие российской угольной отрасли и большой потенциал Арктической зоны».
«Воркутауголь» – крупный производитель угля. По данным «Северстали», на ее долю приходится около 11% производства коксующегося угля в России. Предприятия «Воркутауголь» работают на территории Печорского угольного бассейна. Воркутинский геолого-промышленный район располагает самыми большими в Европе запасами угля (порядка 4 млрд т). В состав компании входят пять подземных шахт, один разрез и несколько вспомогательных предприятий. Объем добычи угля предприятиями компании в 2020 г. составил 10,3 млн т, производство угольного концентрата – 4,7 млн т. В июне компания сообщала, что с I квартала 2022 г. прекратит добывать энергетический уголь (марки ГЖО).
ООО «Русская энергия» создана в январе 2020 г., зарегистрирована в Москве, следует из данных «СПАРК-Интерфакса». Совладельцы «Русской энергии» – председатель совета директоров корпорации Aeon Роман Троценко (70%) и гендиректор «Русской энергии», бывший топ-менеджер А1 Андрей Тясто (30%). Троценко приобрел 70% компании в конце сентября 2021 г.
Корпорации Aeon Романа Троценко принадлежит компания «Северная звезда», реализующая проект по освоению Сырадасайского месторождения угля (запасы 153 млн т) на Таймырском полуострове в Красноярском крае. Запуск добычи запланирован на 2021 г. Объем производства угольного концентрата в рамках проекта должен составить порядка 7 млн т в год после 2026 г. В рамках проекта также планируется построить морской порт «Енисей» грузооборотом до 10 млн т/год, аэродром, электростанцию на 30 МВт, обогатительную фабрику и 61-километровую автодорогу.
Он также добавляет, что добыча на проекте крайне дорогостоящая, а выход концентрата из угля – низкий. Эксперт также отметил, что в состав «Воркутаугля» входят шахты, опасные с точки зрения выбросов метана, и ожидаемое ужесточение технических требований после недавней трагедии на «Листвяжной» (входит в «СДС-уголь») может затруднить работу шахт «Воркутаугля». Гришунин вспоминает, что авария на шахте компании «Северная» в 2016 г. унесла жизни 36 человек.
Лобазов добавляет, что «Северсталь» исторически воспринималась инвесторами как «защитный» актив с наиболее близкой к 100% интеграцией в железную руду и уголь. «Это позволяло инвестору защитить свои вложения от непредсказуемых колебаний цен на сырье и, в частности, было одной из причин такой сильной динамики цен на акции компании в последнее время. С продажей «Воркутаугля» этот инвестиционный кейс для «Северстали» меняется», – говорит аналитик.
Мотивацию Троценко к покупке «Воркутаугля» Гришунин поясняет стратегическим характером актива для его бизнеса. «Прямой синергии с проектом «Северная звезда» не прослеживается. Но учитывая низкий уровень жизни в Воркуте, часть высококвалифицированных горняков из «Воркутаугля» могут перейти в проект на Таймыре», – говорит он. Стратегия «Северстали» предполагает переориентацию на низкоуглеродные технологии плавки, поэтому компания уделяла угольному сегменту недостаточно внимания, предположил аналитик. В свою очередь новый инвестор, по его мнению, сможет увеличить производительность и повысить безопасность объектов добычи.