Высокопроизводительные кластерные решения

Обзор
Кластер серверов представляет собой группу из нескольких машин, которые объединены в единый аппаратно-программный ресурс. Для соединения отдельных серверов в кластер применяются высокоскоростные каналы связи. Пользователи и приложения видят их как единую высокопроизводительную и надежную систему. В зависимости от назначения выделяют три вида кластеров.
Отказоустойчивый кластер / High-Availability cluster (HA)
Это кластер высокой доступности, в котором при отказе одного сервера его функции перенимают на себя другие машины в кластере. Таким образом, сервисы и приложения продолжают работать без остановки благодаря аппаратной избыточности. Чтобы построить отказоустойчивую структуру, требуется минимум два физических сервера с системами хранения данных. В рамках СХД дисковое пространство распределяется между всеми серверами, а для управления виртуальными машинами используют специальное ПО – гипервизор. Виртуальные машины, запущенные на серверах кластера, работают по следующему принципу: если одна из них выходит из строя, в работу автоматически включается вторая.
Применение: везде, где требуется непрерывная работа бизнес-сервисов и поддержка важных баз данных (банк, биржа, круглосуточное производство), электронные торговые площадки.
Преимущества: надежность, высокая доступность сервисов и приложений, сокращение потерь из-за простоев в работе.
Кластер с балансировкой нагрузки / Load balancing cluster
В пределах этого кластера нагрузка, которую создают сервисы и приложения, равномерно распределяется между доступными машинами. Так исключается простой одного сервера, пока второй работает на пределе возможностей. Для распределения запросов в кластере используется один или несколько входных вычислительных узлов, через которые задачи перенаправляются с одной машины на другую.
Применение: ЦОД, комплексы для ERP/CRM-систем, сервисы биллинга в телекоммуникационных системах.
Преимущества: масштабируемость, возможность использования недорогих серверов стандартной архитектуры.
Вычислительный кластер / High-Performance Computing cluster
Кластер построен на основе нескольких серверов, объединенных высокоскоростными линиями передач и специальным ПО. На выходе образуется единая система для комплексных вычислений. Каждый сервер в таком кластере обрабатывает задачу, которая автоматически выделяется ему из общего объема работы.
Применение: аналитика, сбор и обработка данных для Big Data, системы искусственного интеллекта, нейронные сети.
Преимущества: высокая производительность в ресурсоемких задачах, выполнение параллельных вычислений.
Специалисты компании ITELON имеют необходимый опыт и компетенцию для подбора высокопроизводительного кластерного решения для вашего бизнеса. Они разработают и внедрят отказоустойчивую высокопроизводительную систему, используя оборудование ведущих вендоров и современные технологии виртуализации. Мы рекомендуем использовать серверы HPE ProLiant DL380 Gen10 (2U), Dell PowerEdge R740 (2U), Fujitsu PRIMERGY RX2540 M4, Lenovo System x3650 M5 (2U).
Вычислительный кластер
Вычислительный кластер – это набор соединенных между собой компьютеров (серверов), которые работают вместе и могут рассматриваться как единая система. В отличие от грид-вычислений, все узлы компьютерного кластера выполняют одну и ту же задачу и управляются одной системой управления.
Серверы кластера обычно соединяются между собой по быстродействующей локальной сети, причем на каждом из серверов работает собственный экземпляр операционной системы. В большинстве случаев все вычислительные узлы кластера используют одинаковое оборудование и одну и ту же операционную систему. Однако в некоторых инсталляциях, например, с использованием платформы приложений для организации кластеров OSCAR (Open Source Cluster Application Resources), могут использоваться различные операционные системы или разное серверное оборудование.
Кластеры обычно развертываются для большей производительности и доступности, чем то, что можно получить от одного компьютера, пусть даже очень мощного. Часто такое решение более экономично, чем отдельные компьютеры.
Компоненты кластера
Вычислительные кластеры обычно состоят из следующих компонентов:

Виды кластеров
Различают следующие основные виды кластеров:
Кластеры высокой доступности
Кластеры высокой доступности НА (high-availability cluster) известны также как отказоустойчивые (failover) кластеры, построенные по схеме сети с большой избыточностью (redundancy). Они применяются для критических серверных приложений, например сервера баз данных. Компьютерный кластер может называться НА-кластером, если он обеспечивает доступность приложений не менее, чем «пять девяток», т. е. приложение должно быть доступно (uptime) в течение 99,999 % времени за год.
Чрезвычайно высокая доступность в НА-кластерах достигается за счет использования специального программного обеспечения и аппаратных решений со схемами обнаружения отказов, а также благодаря работе по подготовке к отказам.
ПО для НА-кластеров обычно заблаговременно конфигурирует узел на резервном сервере и запускает на нем приложение в фоновом режиме так, чтобы основной экземпляр приложения мог немедленно переключиться на свою реплику на резервном компьютере при отказе основного.
НА-кластеры обычно используются для терминальных серверов, серверов баз данных, почтовых серверов, а также для серверов общего доступа к файлам. Они могут быть развернуты как на одном местоположении («серверной ферме»), так и в географически разнесенных местоположениях.
Но не следует думать, что технология кластера высокой доступности, или вообще кластеризация, могут служить заменой резервному копированию (backup), а также решениям катастрофоустойчивости (disaster recovery).
Кластеры с балансировкой нагрузки
Балансировка нагрузки – это эффективное распределение входящего сетевого трафика в группе (кластере) серверов.
Современные веб-сайты должны одновременно обслуживать сотни тысяч и даже миллионы запросов от пользователей или клиентов и не слишком задерживать их в получении контента: текста, видео или данных приложений. Чем больше серверов будут обслуживать эти запросы, тем лучше будет качество воспринимаемого сервиса для клиентов. Однако может возникнуть ситуация, когда одни серверы сайта будут работать с перегрузкой, а другие будут почти простаивать.
Балансировщик нагрузки направляет запросы клиентов равномерно на все серверы кластера, которые способны ответить на те или иные запросы. Таким образом, балансировщик максимизирует процент использования вычислительной емкости, а также обеспечивает то, что ни один сервер не оказывается перегруженным, вызывая общую деградацию производительности кластера.
Если какой-то сервер отказывает, то балансировщик перенаправляет трафик на оставшиеся серверы. Когда новый сервер добавляется к группе (кластеру), то балансировщик автоматически перераспределяет нагрузку на всех серверах с учетом вновь вступившего в работу.
Таким образом, балансировщик нагрузки выполняет следующие функции:

Работа балансировщика нагрузки
Алгоритмы балансировки нагрузки
Различные алгоритмы балансировки предназначены для разных целей и достижения разных выгод. Можно назвать следующие алгоритмы балансировки:
Программная и аппаратная балансировка нагрузки
Балансировщики нагрузки бывают двух типов: программные и аппаратные. Программные балансировщики можно установить на любой сервер достаточной для задачи емкости. Поставщики аппаратных балансировщиков просто загружают соответствующее программное обеспечение балансировки нагрузки на серверы со специализированными процессорами. Программные балансировщики менее дорогие и более гибкие. Можно также использовать облачные решения сервисов балансировки нагрузки, такие как AWS EC2.
Высокопроизводительные кластеры (HPC)
Высокопроизводительные вычисления HPC (High-performance computing) – это способность обрабатывать данные и выполнять сложные расчеты с высокой скоростью. Это понятие весьма относительное. Например, обычный лэптоп с тактовой частотой процессора в 3 ГГц может производить 3 миллиарда вычислений в секунду. Для обычного человека это очень большая скорость вычислений, однако она меркнет перед решениями HPC, которые могут выполнять квадриллионы вычислений в секунду.
Одно из наиболее известных решений HPC – это суперкомпьютер. Он содержит тысячи вычислительных узлов, которые работают вместе над одной или несколькими задачами, что называется параллельными вычислениями.
HPC очень важны для прогресса в научных, промышленных и общественных областях.
Такие технологии, как интернет вещей IoT (Internet of Things), искусственный интеллект AI (artificial intelligence), и аддитивное производство (3D imaging), требуют значительных объемов обработки данных, которые экспоненциально растут со временем. Для таких приложений, как живой стриминг спортивных событий в высоком разрешении, отслеживание зарождающихся тайфунов, тестирование новых продуктов, анализ финансовых рынков, – способность быстро обрабатывать большие объемы данных является критической.
Чтобы создать HPC-кластер, необходимо объединить много мощных компьютеров при помощи высокоскоростной сети с широкой полосой пропускания. В этом кластере на многих узлах одновременно работают приложения и алгоритмы, быстро выполняющие различные задачи.
Чтобы поддерживать высокую скорость вычислений, каждый компонент сети должен работать синхронно с другими. Например, компонент системы хранения должен быть способен записывать и извлекать данные так, чтобы не задерживать вычислительный узел. Точно так же и сеть должна быстро передавать данные между компонентами НРС-кластера. Если один компонент будет подтормаживать, он снизит производительность работы всего кластера.
Существует много технических решений построения НРС-кластера для тех или иных приложений. Однако типовая архитектура НРС-кластера выглядит примерно так, как показано на рисунке ниже.

Примеры реализации вычислительного кластера
В лаборатории вычислительного интеллекта создан вычислительный кластер для решения сложных задач анализа данных, моделирования и оптимизации процессов и систем.
Кластер представляет собой сеть из 11 машин с распределенной файловой системой NFS. Общее число ядер CPU в кластере – 61, из них высокопроизводительных – 48. Максимальное число параллельных высокоуровневых задач (потоков) – 109. Общее число ядер графического процессора CUDA GPU – 1920 (NVidia GTX 1070 DDR5 8Gb).
На оборудовании кластера успешно решены задачи анализа больших данных (Big Data): задача распознавания сигнала от процессов рождения суперсимметричных частиц, задача классификации кристаллических структур по данным порошковой дифракции, задача распределения нагрузки электросетей путем определения выработки электроэнергии тепловыми и гидроэлектростанциями с целью минимизации расходов, задача поиска оптимального расположения массива кольцевых антенн и другие задачи.

Архитектура вычислительного кластера
Другой вычислительный НРС-кластер дает возможность выполнять расчеты в любой области физики и проводить многодисциплинарные исследования.

Графические результаты расчета реактивного двигателя, полученные на НРС-клатере (источник: БГТУ «ВОЕНМЕХ»)
На рисунке показана визуализация результатов расчета реактивного двигателя, зависимость скорости расчетов и эффективности вычислений от количества ядер процессора.
Про кластер серверов 1С
Кластер — это разновидность параллельной
или распределённой системы, которая:
1. состоит из нескольких связанных
между собой компьютеров;
2. используется как единый,
унифицированный компьютерный ресурс
Дано: есть бизнес-приложение (например, ERP-система), с которым работают одновременно тысячи (возможно, десятки тысяч) пользователей.
К желаемому результату мы пришли не сразу.
В этой статье расскажем о том, какие бывают кластеры, как мы выбирали подходящий нам вид кластера и о том, как эволюционировал наш кластер от версии к версии, и какие подходы позволили нам в итоге создать систему, обслуживающую десятки тысяч одновременных пользователей.

Как писал автор эпиграфа к этой статье Грегори Пфистер в своей книге «In search of clusters», кластер был придуман не каким-либо конкретным производителем железа или софта, а клиентами, которым не хватало для работы мощностей одного компьютера или требовалось резервирование. Случилось это, по мнению Пфистера, ещё в 60-х годах прошлого века.
Традиционно различают следующие основные виды кластеров:
Для тех, кто не в курсе, коротко расскажу, как устроены бизнес-приложения 1С. Это приложения, написанные на предметно-ориентированном языке, «заточенном» под автоматизацию учётных бизнес-задач. Для выполнения приложений, написанных на этом языке, на компьютере должен быть установлен рантайм платформы 1С:Предприятия.
1С:Предприятие 8.0
Первая версия сервера приложений 1С (еще не кластер) появилась в версии платформы 8.0. До этого 1С работала в клиент-серверном варианте, данные хранились в файловой СУБД или MS SQL, а бизнес-логика работала исключительно на клиенте. В версии же 8.0 был сделан переход на трехзвенную архитектуру «клиент – сервер приложений – СУБД».
Сервер 1С в платформе 8.0 представлял собой СОМ+ сервер, умеющий исполнять прикладной код на языке 1С. Использование СОМ+ обеспечивало нам готовый транспорт, позволяющий клиентским приложениям общаться с сервером по сети. Очень многое в архитектуре и клиент-серверного взаимодействия, и прикладных объектов, доступных разработчику 1С, проектировалось с учетом использования СОМ+. В то время в архитектуру не было заложено отказоустойчивости, и падение сервера вызывало отключение всех клиентов. При падении серверного приложения СОМ+ поднимал его при обращении к нему первого клиента, и клиенты начинали свою работу с начала – с коннекта к серверу. В то время всех клиентов обслуживал один процесс.
1С:Предприятие 8.1
В следующей версии мы захотели:
Так в версии 8.1 появился первый кластер. Мы реализовали свой протокол удаленного вызова процедур (поверх ТСР), который по внешнему виду выглядел для конечного потребителя-клиента практически как СОМ+ (т.е. нам практически не пришлось переписывать код, отвечающий за клиент-серверные вызовы). При этом сервер, реализованный нами на С++, мы сделали платформенно-независимым, способным работать и на Windows, и на Linux.
На смену монолитному серверу версии 8.0 пришло 3 вида процессов – рабочий процесс, обслуживающий клиентов, и 2 служебных процесса, поддерживающих работу кластера:
Клиент на протяжении сессии работал с одним рабочим процессом, падение рабочего процесса означало для всех клиентов, которых этот процесс обслуживал, аварийное завершение сессии. Остальные клиенты продолжали работу.
1С:Предприятие 8.2
В версии 8.2 мы захотели, чтобы приложения 1С могли запускаться не только в нативном (исполняемом) клиенте, а ещё и в браузере (без модификации кода приложения). В связи с этим, в частности, встала задача отвязать текущее состояние приложения от текущего соединения с рабочим процессом rphost, сделать его stateless. Как следствие возникло понятие сеанса и сеансовых данных, которые нужно было хранить вне рабочего процесса (потому что stateless). Был разработан сервис сеансовых данных, хранящий и кэширующий сеансовую информацию. Появились и другие сервисы — сервис управляемых транзакционных блокировок, сервис полнотекстового поиска и т.д.
В этой версии также появились несколько важных нововведений – улучшенная отказоустойчивость, балансировка нагрузки и механизм резервирования кластеров.
Отказоустойчивость
Поскольку процесс работы стал stateless и все необходимые для работы данные хранились вне текущего соединения «клиент – рабочий процесс», в случае падения рабочего процесса клиент при следующем обращении к серверу переключался на другой, «живой» рабочий процесс. В большинстве случаев такое переключение происходило незаметно для клиента.
Механизм работает так. Если клиентский вызов к рабочему процессу по какой-то причине не смог исполниться до конца, то клиентская часть способна, получив ошибку вызова, этот вызов повторить, переустановив соединение с тем же рабочим процессом или с другим. Но повторять вызов можно не всегда; повтор вызова означает, что мы отправили вызов на сервер, а результата не получили. Мы стараемся повторить вызов, при этом при выполнении повторного вызова мы оцениваем, каков результат на сервере был у предшествующего вызова (информация об этом сохраняется на сервере в данных сеанса), потому что если вызов успел там «наследить» (закрыть транзакцию, сохранить сеансовые данные и т.п.) – то просто так повторять его нельзя, это приведет к рассогласованию данных. Если повторять вызов нельзя, клиент получит сообщение о неисправимой ошибке, и клиентское приложение придется перезапустить. Если же вызов «наследить» не успел (а это наиболее частая ситуация, т.к. многие вызовы не меняют данных, например, отчеты, отображение данных на форме и т.п., а те, которые меняют данные – пока транзакция не зафиксирована или пока изменение сеансовых данных не отправлено в менеджер – следов вызов не оставил) — его можно повторить без риска рассогласования данных. Если рабочий процесс упал или произошел обрыв сетевого соединения – такой вызов повторяется, и эта «катастрофа» для клиентского приложения происходит полностью незаметно.
Балансировка нагрузки
Задача балансировки нагрузки в нашем случае звучит так: в систему заходит новый клиент (или уже работающий клиент совершает очередной вызов). Нам надо выбрать, на какой сервер и в какой рабочий процесс направить вызов клиента, чтобы обеспечить клиенту максимальное быстродействие.
Это стандартная задача для кластера с балансировкой нагрузки. Есть несколько типовых алгоритмов её решения, например:
Запрос от нового клиента адресуется на наиболее производительный на данный момент сервер.
Запрос от существующего клиента в большинстве случаев адресуется на тот сервер и в тот рабочий процесс, в который адресовался его предыдущий запрос. С работающим клиентом связан обширный набор данных на сервере, передавать его между процессами (а тем более между серверами) – довольно накладно (хотя мы умеем делать и это).
Запрос от существующего клиента передается в другой рабочий процесс в двух случаях:
Резервирование кластеров
Мы решили повысить отказоустойчивость кластера, прибегнув к схеме Active / passive. Появилась возможность конфигурировать два кластера – рабочий и резервный. В случае недоступности основного кластера (сетевые неполадки или, например, плановое техобслуживание) клиентские вызовы перенаправлялись на резервный кластер.
Однако эта конструкция была довольно сложна в настройке. Администратору приходилось вручную собирать две группы серверов в кластеры и конфигурировать их. Иногда администраторы допускали ошибки, устанавливая противоречащие друг другу настройки, т.к. не было централизованного механизма проверки настроек. Но, тем не менее, этот подход повышал отказоустойчивость системы.
1С:Предприятие 8.3
В версии 8.3 мы существенно переписали код серверной части, отвечающий за отказоустойчивость. Мы решили отказаться от схемы Active / passive кластеров ввиду сложности её конфигурирования. В системе остался только один отказоустойчивый кластер, состоящий из любого количества серверов – это ближе к схеме на Active / active, в которой запросы на отказавший узел распределяются между оставшимися рабочими узлами. За счет этого кластер стал проще в настройке. Ряд операций, повышающих отказоустойчивость и улучшающих балансировку нагрузки, стали автоматизированными. Из важных нововведений:
Главная идея этих наработок – упростить работу администратора, позволяя ему настраивать кластер в привычных ему терминах, на уровне оперирования серверами, не опускаясь ниже, а также минимизировать уровень «ручного управления» работой кластера, дав кластеру механизмы для решения большинства рабочих задач и возможных проблем «на автопилоте».
Три звена отказоустойчивости
Как известно, даже если компоненты системы по отдельности надёжны, проблемы могут возникнуть там, где компоненты системы вызывают друг друга. Мы хотели свести количество мест, критичных для работоспособности системы, к минимуму. Важным дополнительным соображением была минимизация переделок прикладных механизмов в платформе и исключение изменений в прикладных решениях. В версии 8.3 появилось 3 звена обеспечения отказоустойчивости «на стыках»:
В заключение
Благодаря механизму отказоустойчивости приложения, созданные на платформе 1С:Предприятие, благополучно переживают разные виды отказов рабочих серверов в кластере, при этом бо́льшая часть клиентов продолжают работать без перезапуска.
Бывают ситуации, когда мы не можем повторить вызов, или падение сервера застает платформу в очень неудачный момент времени, например, в середине транзакции и не очень понятно, что с ними делать. Мы стараемся обеспечить статистически хорошую выживаемость клиентов при падении серверов в кластере. Как правило, средние потери клиентов за отказ сервера – единицы процентов. При этом все «потерянные» клиенты могут продолжить работу в кластере после перезапуска клиентского приложения.
Надежность кластера серверов 1С в версии 8.3 существенно повысилась. Уже давно не редкость внедрения продуктов 1С, где количество одновременно работающих пользователей достигает нескольких тысяч. Есть и внедрения, где одновременно работают и 5 000, и 10 000 пользователей — например, внедрение в «Билайне», где приложение «1С: Управление Торговлей» обслуживает все салоны продаж «Билайн» в России, или внедрение в грузоперевозчике «Деловые Линии», где приложение, самостоятельно созданное разработчиками ИТ-отдела «Деловых Линий» на платформе 1С:Предприятие, обслуживает полный цикл грузоперевозок. Наши внутренние нагрузочные тесты кластера эмулируют одновременную работу до 20 000 пользователей.
В заключение хочется кратко перечислить что ещё полезного есть в нашем кластере (список неполный):
Что такое серверный кластер?
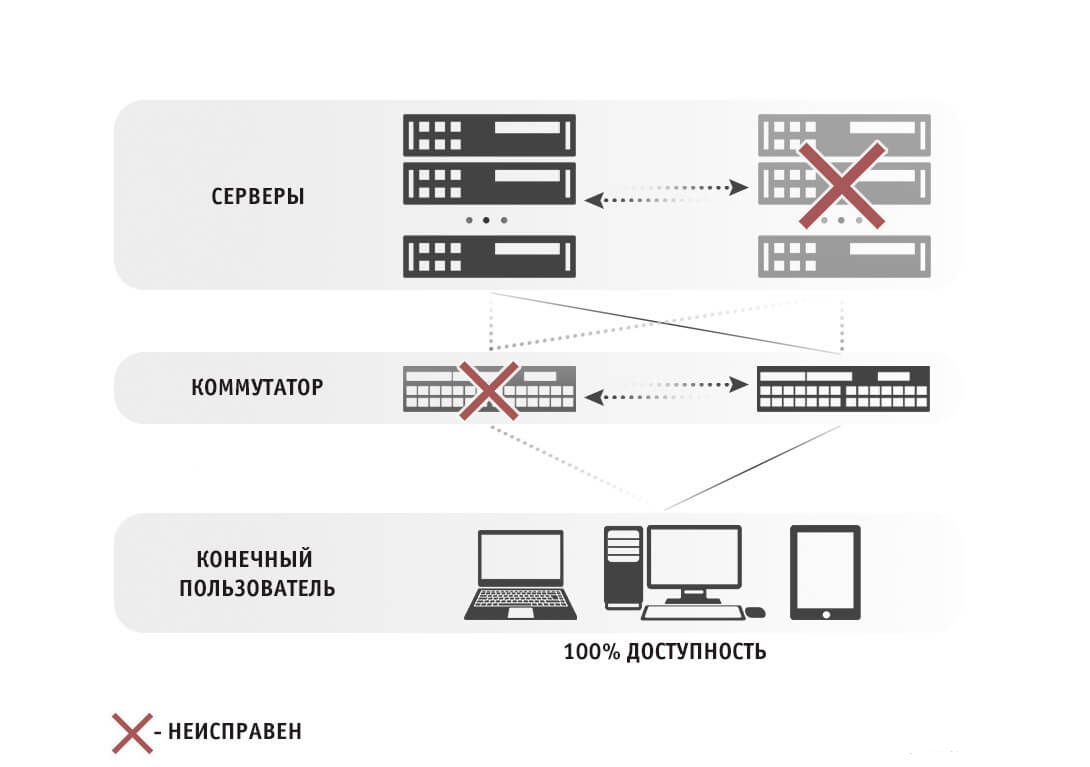
Виды кластеров:
Отказоустойчивые. Несколько серверов объединяются с целью дублирования друг друга.
Высокопроизводительные. На группу машин отправляются данные для обработки — кластер распределяет задачи по всем участникам для ускорения обработки.
Балансировщики. Все запросы на серверы распределяются в случайном порядке между нодами кластера.
Принято считать, что кластеры серверов делятся на две модели:
Первая — это использование единого массива хранения информации, что дает возможность более быстрого переподключения при сбое. Однако в случае с объемной базой данных и большим количеством аппаратных единиц в системе, возможно падение производительности.
Вторая — это модель, при которой серверы независимы, как и их периферия. В случае отказа перераспределение происходит между серверами. Здесь ситуация обратная — трафик в системе более свободен, однако, усложняется и ограничивается пользование общей базой данных.
Кластерная защита от сбоев и отключений
Основным обоснованием для кластеров серверов является защита от простоев и сбоев. Как упомянуто выше, кластерные серверы обеспечивают повышенную защиту от полного отключения сети во время сбоя питания, и предназначены для защиты от трех основных типов сбоев:
Сбой приложения/службы: сбой, который влияет на критически важные приложения и службы в сети.
Системный/аппаратный сбой: выходы из строя, которые влияют на такие компоненты, как процессоры, память, адаптеры, диски и источники питания.
Сбой датацентра: сбои датацентров, которые затрагивают несколько мест, как правило, вызваны стихийными бедствиями, которые приводят к массовым отключениям электроэнергии.
Основные возможности кластера серверов
кластер серверов может функционировать на одном или нескольких компьютерах (рабочих серверах);
на каждом рабочем сервере может функционировать один или несколько рабочих процессов, обслуживающих клиентские соединения в рамках данного кластера;
подключение новых клиентов к рабочим процессам кластера выполняется на основе анализа долгосрочной статистики загруженности рабочих процессов;
взаимодействие процессов кластера с клиентскими приложениями, между собой и с сервером баз данных осуществляется по протоколу TCP/IP;
процессы кластера сервера могут быть запущены как приложение, или как сервис.
Общая схема клиент-серверного варианта работы
В клиент-серверном варианте работы клиентское приложение взаимодействует с кластером серверов, который, в свою очередь, осуществляет взаимодействие с сервером баз данных.
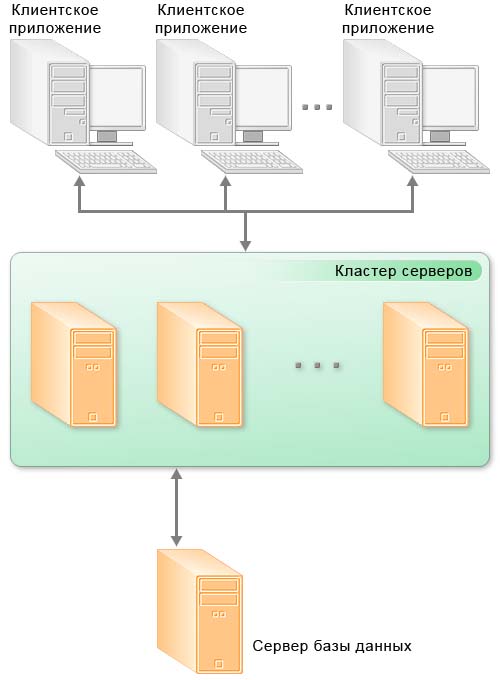
Один из компьютеров, входящих в состав кластера серверов, является центральным сервером кластера. Центральный сервер, помимо обслуживания клиентских соединений, управляет работой всего кластера и хранит реестр кластера.
Для клиентского соединения кластер адресуется по имени центрального сервера и номеру IP порта. Если используется стандартный IP порт, то достаточно указания одного имени центрального сервера.
При установке соединения клиентское приложение обращается к центральному серверу кластера. Центральный сервер, на основе анализа статистики загруженности рабочих процессов, направляет клиентское приложение к конкретному рабочему процессу, который будет его обслуживать. Этот процесс может находиться как на центральном сервере, так и на любом рабочем сервере кластера.
Рабочий процесс выполняет аутентификацию пользователя и обслуживает соединение до окончания сеанса работы клиента с данной информационной базой.
Зачем кластеризовать ваши серверы?
Существует три основных причины кластеризации серверов. Это доступность, масштабируемость и надежность. Ключ к защищенной ИТ-инфраструктуре лежит в избыточности. Создание кластера серверов в одной сети обеспечивает максимальную избыточность и гарантирует, что одна ошибка не приведет к отключению всей сети.