Что такое Service Mesh?
И снова здравствуйте. В преддверии старта курса «Архитектор ПО» мы подготовили еще один полезный перевод.

Service Mesh – это конфигурируемый инфраструктурный уровень с низкой задержкой, который нужен для обработки большого объема сетевых межпроцессных коммуникаций между программными интерфейсами приложения (API). Service Mesh обеспечивает быструю, надёжную и безопасную коммуникацию между контейнеризированными и часто эфемерными сервисами инфраструктуры приложений. Service Mesh предоставляет такие возможности, как обнаружение сервисов, балансировку нагрузки, шифрование, прозрачность, трассируемость, аутентификацию и авторизацию, а также поддержку шаблона автоматического выключения (circuit breaker).
Service Mesh обычно реализуется путем предоставления каждому экземпляру сервиса экземпляра прокси, который называется Sidecar. Sidecar обрабатывают коммуникации между сервисами, производят мониторинг и устраняют проблемы безопасности, то есть все, что может быть абстрагировано от отдельных сервисов. Таким образом, разработчики могут писать, поддерживать и обслуживать код приложения в сервисах, а системные администраторы могут работать с Service Mesh и запускать приложение.
Istio от Google, IBM и Lyft, на данный момент является самый известной Service Mesh-архитектурой. А Kubernetes, который изначально разрабатывался в Google, сейчас является единственным фреймворком для оркестрации контейнеров, который поддерживается Istio. Вендоры пытаются создать коммерческие поддерживаемые версии Istio. Интересно, что нового они смогут привнести в проект с открытым исходным кодом.
Однако Istio – это не единственный вариант, поскольку разрабатываются и другие реализации Service Mesh. Паттерн sidecar proxy является наиболее популярной реализацией, как можно судить по проектам Buoyant, HashiCorp, Solo.io и другим. Существуют и альтернативные архитектуры: технологический инструментарий Netflix – это один из подходов, где функционал Service Mesh реализуется за счет библиотек Ribbon, Hysterix, Eureka, Archaius, а также таких платформ, как Azure Service Fabric.
Service Mesh также имеет свою собственную терминологию для компонентов-сервисов и функций:
Control Plane в Service Mesh распределяет конфигурацию между Sidecar Proxy и Data Plane.
Часто архитектура Service Mesh применяется для решения сложных операционных задач с использованием контейнеров и микросервисов. Пионерами в области микросервисов являются такие компании как Lyft, Netflix и Twitter, которые предоставляют стабильно работающие сервисы миллионам пользователей по всему миру. (Здесь вы можете познакомиться с подробным описанием некоторых архитектурных задач, с которыми столкнулся Netflix). Для менее требовательных прикладных задач скорее всего будет достаточно более простых архитектур.
Архитектура Service Mesh вряд ли когда-нибудь станет ответом на все вопросы, связанные с работой приложений и их доставкой. Архитекторы и разработчики обладают огромным арсеналом инструментов, и только один из них — молоток, который среди множества задач должен решать лишь одну – забивать гвозди. Microservices Reference Architecture от NGINX, например, включает в себя несколько различных моделей, которые дают непрерывный спектр подходов к решению задач с помощью микросервисов.
Элементы, которые объединяются в архитектуре Service Mesh, такие как NGINX, контейнеры, Kubernetes и микросервисы в качестве архитектурного подхода, могут быть не менее продуктивно использованы и в реализациях без Service Mesh. Например, Istio был разработан как полноценная архитектура Service Mesh, но модульность говорит о том, что разработчики могут выбирать и применять только необходимые им компоненты технологий. Помня об этом, необходимо сформировать четкое понимание концепции Service Mesh, даже если вы не уверены в том, что сможете когда-нибудь полноценно ее реализовать в приложении.
Service mesh — это всё ещё сложно
Прим. перев.: эта небольшая статья Lin Sun из IBM в блоге CNCF — занятная иллюстрация тех сложностей, над преодолением которых сейчас трудятся инженеры популярных реализаций service mesh. С ними становится понятным, почему порог вхождения у этих продуктов остаётся довольно большим.
В августе этого года на конференции ServiceMeshCon EU мы с William Morgan из Linkerd выступили с совместным докладом под названием «Service mesh is still hard». William рассказал об инновациях в Linkerd, в то время как я затронула нововведения в Istio. Оба проекта, очевидно, активно работают над тем, чтобы упростить переход обычных пользователей на service mesh.
Этот слайд (из видео с недавним выступлением William Morgan и Lin Sun) лаконично подытоживает актуальные плюсы и минусы сервисных сеток
Сегодня service mesh стали более зрелыми, чем были год или пару лет назад. Однако они по-прежнему сложны для понимания большинства пользователей.
Обычно выделяют два типа технических ролей для сервисной сетки: владельцы платформ и владельцы сервисов. Как следует из названия, владельцы платформ (также называемые mesh-админами) контролируют сервисную платформу и определяют общую стратегию и реализацию перехода на SM для владельцев сервисов. Владельцы сервисов контролируют один или несколько сервисов в SM.
Развитие данной технологии упростило использование сервисных сеток владельцами платформ. Ключевые проекты в этой области внедряют различные способы, упрощающие конфигурирование сети, настройку политик безопасности и общую визуализацию. Например, в Istio владельцы платформ могут определять политики аутентификации и авторизации на любом нужном уровне. Владельцы платформ могут настраивать на входном шлюзе хосты, порты или параметры для TLS, делегируя конфигурацию маршрутизации и задание политик для трафика целевого сервиса владельцам этого сервиса. Владельцы сервисов, следующие проверенным и универсальным сценариям, выигрывают от улучшений в удобстве использования Istio и легко переносят свои микросервисы в mesh. С другой стороны, владельцам сервисов, реализующим менее распространенные сценарии, приходится многому учиться и многое узнавать.
Я считаю, что service mesh сложна для понимания по следующим причинам:
1. Отсутствие четкого представления о том, нужна ли вам сервисная сетка
Прежде чем начинать сравнивать различные SM и заниматься конкретной реализацией, необходимо знать, поможет ли сервисная сетка в вашем сценарии использования. К сожалению, на этот вопрос нет однозначного ответа, поскольку существует масса факторов, которые необходимо учитывать:
2. Сервис может сломаться сразу же после подключения sidecar-контейнера
В прошлый День благодарения я пыталась помочь пользователю запустить сервис ZooKeeper в SM, используя последние версии соответствующих Helm-чартов. ZooKeeper работает в Kubernetes как StatefulSet. При попытке подключить sidecar с Envoy в pod’ы ZooKeeper те отказывались работать и постоянно перезапускались, поскольку не могли определить лидера и установить связь друг с другом. По умолчанию ZooKeeper использует IP-адрес pod’а для связи между серверами. Однако Istio и другие сервисные сетки требуют, чтобы рабочие нагрузки функцонировали с localhost’ом (127.0.0.1) внутри pod’а. В результате серверы ZooKeeper оказались не способны связываться друг с другом:
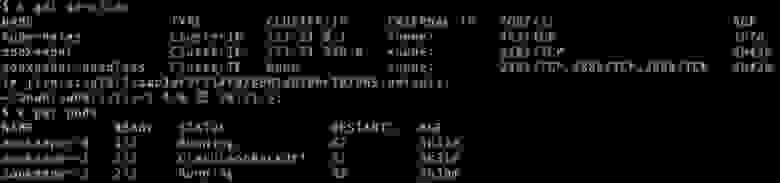
Совместными с upstream-сообществом усилиями мы придумали временное решение в конфигурации для ZooKeeper’а (а также для Cassandra, Elasticsearch, Redis и Apache NiFi)… Не сомневаюсь, что есть и другие приложения, не совместимые с sidecar-контейнерами. Пожалуйста, расскажите сообществу о них.
3. Сервис может демонстрировать странное поведение во время запуска или остановки
Контейнер с приложением может запуститься до sidecar’а и вызвать сбой приложения. То же самое справедливо для остановки: sidecar может завершить работу до основного контейнера.
В Kubernetes отсутствует стандартный способ задавать зависимости контейнеров. Существует соответствующее предложение — Sidecar Kubernetes Enhancement Proposal (KEP), — однако оно пока не реализовано (более того, в октябре его признали неправильным шагом в развитии Kubernetes и закрыли в надежде на появление иных подходов, реализуемых в других KEP’ах, — прим. перев.). Кроме того, некоторое время обязательно уйдет на стабилизацию этой функции. Тем временем владельцы сервисов могут столкнуться с неожиданном поведением во время запуска или остановки.
Чтобы справиться с этой проблемой, Istio внедрил в конфигурацию глобальную опцию для владельцев платформ, позволяющую отложить запуск приложения до тех пор, пока sidecar не будет готов. В скором времени планируется добавить аналогичную опцию на уровне pod’а.
4. Конфигурацию сервиса можно не менять, но вносить изменения в код придется в любом случае
Одна из амбициозных целей проекта service mesh — реализовать концепцию «нулевой» конфигурации для владельцев сервисов. Некоторые проекты (вроде Istio) добавили интеллектуальное обнаружение протоколов, чтобы упростить переход на SM. При этом мы по-прежнему рекомендуем пользователям явно прописывать протоколы в production. После добавления опции appProtocol в Kubernetes у владельцев сервисов появился стандартный способ настройки протоколов приложения для сервисов Kubernetes, работающих в более новых версиях K8s (например, в 1.19) [стабилизация этой фичи случилась в K8s 1.20 — прим. перев.].
К сожалению, аналогичная «нулевая» концепция для кода невозможна, если мы хотим в полной мере воспользоваться преимуществами service mesh.
5. Владелец сервиса должен понимать нюансы настройки на стороне клиента и сервиса
До работы над service mesh я понятия не имела, что в Envoy так много настроек, связанных с таймаутами и повторными попытками. Большинству пользователей знакомы таймауты запросов, таймауты простоя и количество повторных попыток, но есть ряд нюансов и сложностей:
Заключение
Надеюсь, перечисленные выше тонкости найдут у вас отклик независимо от того, на какой стадии перехода к использованию service mesh вы находитесь. С нетерпением жду возможности познакомиться с идеями других проектов, поскольку все мы усиленно работаем на тем, чтобы сделать service mesh как можно более скучными (в хорошем смысле этого слова) и максимально полезными.
Зачем мы делаем Enterprise Service Mesh
Service Mesh — известный архитектурный паттерн для интеграции микросервисов и перехода на облачную инфраструктуру. Сегодня в облачно-контейнерном мире обойтись без него довольно сложно. На рынке уже доступны несколько open-source реализаций service mesh, но их функциональности, надежности и безопасности далеко не всегда достаточно, особенно когда речь идет о требованиях больших финансовых компаний масштаба всей страны. Поэтому мы в Сбертехе решили кастомизировать Service Mesh и хотим рассказать о том, что в Service Mesh круто, что не очень и что мы с этим собираемся сделать.
Популярность шаблона Service Mesh растет с популярностью облачных технологий. Он представляет собой выделенный инфраструктурный слой, который упрощает взаимодействие между различными сетевыми сервисами. Современные облачные приложения состоят из сотен и даже тысяч таких сервисов, каждый из которых может иметь тысячи копий.
Взаимодействие между этими сервисами и управление ими — ключевая задача Service Mesh. Фактически это сетевая модель из множества прокси, управляемая централизованно и выполняющая набор весьма полезных функций.
На уровне прокси (data plane):
Для чего нужен Service Mesh в корпоративном секторе
Использование Service Mesh приносит множество очевидных преимуществ. Прежде всего, это просто удобно разработчикам: для написания кода появляется технологическая платформа, которая существенно упрощает интеграцию в облачную инфраструктуру за счет того, что транспортный слой полностью изолирован от прикладной логики.
Кроме того, Service Mesh упрощает взаимоотношения поставщиков и потребителей. Сегодня поставщикам и потребителям API гораздо проще договориться об интерфейсах и контрактах самостоятельно, не привлекая для этого специального интеграционного посредника и арбитра – корпоративную сервисную шину. Такой подход существенно влияет на два показателя. Увеличивается скорость вывода новой функциональности на рынок (time-to-market), но при этом повышается стоимость решения, так как интеграцию приходится делать самостоятельно. Использование Service Mesh командами разработки бизнес-функциональности позволяет сохранить здесь баланс. В итоге поставщики API могут сфокусироваться исключительно на прикладной составляющей своего сервиса и просто опубликовать его в Service Mesh — API сразу станет доступен всем клиентам, а качество интеграции будет production ready и не потребует ни одной строчки дополнительного кода.
Следующим преимуществом является то, что разработчик, используя Service Mesh, фокусируется исключительно на бизнес-функциональности — на продуктовой, а не на технологической составляющей своего сервиса. Например, уже не приходится думать о том, что в ситуации, когда сервис будет вызываться по сети, где-то может произойти обрыв соединения. Кроме того, Service Mesh помогает сбалансировать трафик между копиями одного и того же сервиса: если одна из копий «умерла», то система переключит весь трафик на оставшиеся живые копии.
Service Mesh — это хорошая основа для создания распределенных приложений, которая скрывает от клиента детали обеспечения вызовов его сервисов как изнутри, так и снаружи. Все приложения, использующие Service Mesh, на транспортном уровне изолированы и от сети, и друг от друга: никакой связи между ними нет. При этом разработчик получает полный контроль над своими сервисами.
Нельзя не отметить, что обновление распределенных приложений в среде, где используется Service Mesh, становится проще. Например, blue/green-развертывание, при котором для установки доступны две среды приложения, одна из которых не обновляется и находится в режиме ожидания. Откат на прошлую версию в случае неудачного релиза осуществляется специальным роутером, с ролью которого прекрасно справляется Service Mesh. Для обкатки новой версии можно использовать и канареечный релиз — переключить на новую версию только 10% трафика или запросы от пилотной группы клиентов. Основной трафик идет на старую версию, ничего не ломается.
Также Service Mesh дает нам контроль SLA в реальном времени. Система распределенных прокси не позволит завалить сервис, когда кто-то из клиентов превысит выданную ему квоту. Если пропускная способность по API ограничена, никто не сможет заддосить его большим количеством транзакций: Service Mesh стоит перед сервисом и не пропускает лишний трафик. Он просто будет отбиваться в интеграционном слое, а сами сервисы продолжат работать, не замечая этого.
Если компания хочет сократить расходы на развитие интеграционных решений, Service Mesh также выручает: на его open-source версии можно перейти с коммерческих продуктов. Наш Enterprise Service Mesh базируется на open-source версии Service Mesh.
Еще одно преимущество — наличие единого полноценного набора интеграционных сервисов. Поскольку вся интеграция строится через этот промежуточный слой, мы можем управлять всем интеграционным трафиком и связями между приложениями, которые формируют бизнес-ядро компании. Это очень удобно.
И наконец Service Mesh стимулирует компанию к переходу на динамическую инфраструктуру. Сейчас многие смотрят в сторону контейнеризации. Распиливать монолит на микросервисы, все это красиво внедрять — тема находится на подъеме. Но когда ты пытаешься перевести на новые рельсы систему, которая уже много лет в продакшне, то сразу сталкиваешься с целым рядом проблем: затолкать все это в контейнеры и развернуть на платформе непросто. А внедрение, синхронизация и взаимодействие этих распределенных компонентов —еще одна сложнейшая тема. Как они будут друг с другом общаться? Не будет ли каскадных сбоев? Service Mesh позволяет решить часть этих проблем и облегчить миграцию со старой архитектуры на новую за счет того, что про логику сетевого обмена можно забыть.
Зачем нужна кастомизация Service Mesh
У нас в компании уживаются вместе сотни систем и модулей, а runtime очень нагружен. Так что простого паттерна, когда одна система вызывает другую и получает ответ, недостаточно, потому что в production мы хотим большего. Что еще нужно от корпоративного Service Mesh?
Сервис обработки событий
Представим, что нам нужно сделать real-time event processing — систему, которая в реальном времени анализирует действия клиента и может сразу сделать ему релевантное предложение. Чтобы реализовать подобную функциональность, используется архитектурный паттерн под названием event-driven architecture (EDA). Ни один из актуальных Service Mesh такие паттерны нативно не поддерживает, а ведь это очень важно, особенно для банка!
Довольно странно, что «удаленный вызов» Remote Procedure Call (RPC) поддерживают все версии Service Mesh, а с EDA они не дружат. Потому что Service Mesh — это подобие современной распределенной интеграции, а EDA — очень актуальный архитектурный паттерн, который позволяет делать уникальные вещи в плане клиентского опыта.
Наш Enterprise Service Mesh данную проблему должен решать. Кроме того, мы хотим видеть в нем реализацию гарантированной доставки, потоковой и комплексной обработки событий с использованием разнообразных фильтров и шаблонов.
Сервис передачи файлов
Помимо EDA было бы неплохо иметь возможность передавать файлы: в масштабах Enterprise очень часто возможна только файловая интеграция. В частности, используется архитектурный паттерн ETL (Extract, Transform, Load — «извлечение, преобразование, загрузка»). В нем, как правило, все обмениваются исключительно файлами: используются большие данные, которые нецелесообразно пихать отдельными запросами. Возможность нативной поддержки передачи файлов в Enterprise Service Mesh дает необходимую для бизнеса гибкость.
Сервис оркестрации
В крупных организациях почти всегда есть разные команды, которые делают разные продукты. Например, в банке одни команды работают с депозитами, а другие — с кредитными продуктами, и таких кейсов достаточно много. Это разные люди, разные команды, которые делают свои продукты, разрабатывают свои API и предоставляют их другим. И очень часто возникает потребность в композиции этих сервисов, а также имплементации сложной логики последовательного вызова набора API. Для решения данной проблемы необходимо решение в интеграционном слое, которое позволит упростить всю эту композитную логику (вызов нескольких API, описание маршрута запросов и т.д.). Это и есть сервис оркестрации в Enterprise Service Mesh.
AI и ML
Когда микросервисы общаются через единый интеграционный слой, Service Mesh, естественно, знает все о вызовах каждого сервиса. Мы собираем телеметрию: кто кого вызывал, когда, как долго, сколько раз и так далее. Когда этих сервисов сотни тысяч, а вызовов — миллиарды, то все это накапливается и формирует Big Data. Эти данные можно проанализировать средствами ИИ, machine learning и пр., а потом сделать на основе результатов анализа какие-то полезные вещи. Было бы уместно хотя бы частично передать искусственному интеллекту управление всем этим сетевым трафиком и вызовами приложений, интегрированных в Service Mesh.
Сервис API Gateway (Шлюз API)
Как правило, в Service Mesh есть прокси и сервисы, которые обращаются друг с другом внутри доверенного периметра. Но существуют еще и внешние контрагенты. Требования к API, предоставляемым этой группе потребителей, намного серьезнее. Эту задачу мы делим на две основные части.
Сервис поддержки специфических протоколов и форматов данных (шлюз АС)
На текущий момент большинство решений Service Mesh умеют нативно работать только с трафиком HTTP и HTTP2 или в урезанном режиме на уровне TCP/IP. У Enterprise Service Mesh появляется много других весьма специфических протоколов передачи данных. Одни системы могут использовать брокеры сообщений, другие интегрированы на уровне баз данных. Если в компании есть SAP, то он также может использовать собственную систему интеграции. Причем все это работает и является важной частью бизнеса.
Нельзя просто сказать: «Давайте откажемся от legacy и сделаем новые системы, которые смогут использовать Service Mesh». Чтобы подружить все старые системы с новыми (на микросервисной архитектуре), системам, которые могут использовать Service Mesh, понадобится какой-то адаптер, посредник, шлюз. Согласитесь, было бы неплохо, если бы он поставлялся в коробке вместе с сервисом. Шлюз АС как раз и может поддержать любой вариант интеграции. Только представьте, вы просто устанавливаете Enterprise Service Mesh, и он уже готов взаимодействовать со всеми протоколами, которые вам нужны. Для нас такой подход очень важен.
Примерно так мы представляем корпоративную версию Service Mesh (Enterprise Service Mesh). Описанная кастомизация решает большинство проблем, возникающих при попытках использовать готовые open-source версии интеграционной платформы. Появившись всего пару лет назад, архитектура Service Mesh продолжает развиваться, и мы рады, что можем внести вклад в ее развитие. Надеемся, что наш опыт будет вам полезен.
Сценарии использования service mesh
Прим. перев.: автор это статьи (Luc Perkins) — developer advocate в организации CNCF, являющейся домом для таких Open Source-проектов, как Linkerd, SMI (Service Mesh Interface) и Kuma (кстати, вы тоже задумывались, почему в этом списке нет Istio. ). В очередной раз пытаясь принести в DevOps-сообщество лучшее понимание в модный хайп под названием «service mesh», он приводит 16 характерных возможностей, которые предоставляют подобные решения.
Сегодня service mesh ― одна из самых горячих тем в области программной инженерии (и по праву!). Я считаю эту технологию невероятно перспективной и мечтаю стать свидетелем ее широкого распространения (конечно, когда это имеет смысл). Тем не менее, она до сих пор окружена ореолом таинственности для большинства людей. При этом даже те, кто хорошо знаком с ней, нередко затрудняются сформулировать ее плюсы и что именно она собой представляет (включая и вашего покорного слугу). В статье я попытаюсь исправить ситуацию, перечислив различные сценарии использования «сервисных сеток»*.
* Прим. перев.: здесь и далее в статье будет использоваться именно такой перевод («сервисная сетка») для всё ещё нового термина service mesh.
Но сперва хочу сделать несколько замечаний:
1. Обнаружение сервисов
TL;DR: Подключайтесь к другим сервисам в сети с помощью простых имен.
Плюс ко всему, когда один сервис находит другой, он должен иметь возможность посылать запросы этому сервису, не опасаясь, что они окажутся на входе у его неработающего экземпляра. Другими словами, service mesh должна следить за работоспособностью всех экземпляров сервисов и поддерживать список хостов в максимально актуальном состоянии.
Каждая service mesh реализует механизм обнаружения сервисов по-своему. На данный момент самым распространенным способом является делегирования внешним процессам вроде DNS Kubernetes. В прошлом в Twitter для этих целей мы использовали систему имен Finagle. Кроме того, технология service mesh делает возможным появление пользовательских механизмов именования (хотя я еще не встречал ни одной реализации SM с таким функционалом).
2. Шифрование
TL;DR: Избавьтесь от незашифрованного трафика между сервисами и пускай этот процесс будет автоматизированным и масштабируемым.
Приятно осознавать, что злоумышленники не могут проникнуть в вашу внутреннюю сеть. Сетевые экраны прекрасно справляются с этим. Но что произойдет, если хакер все же проникнет внутрь? Он сможет делать с внутрисервисным трафиком все, что пожелает? Давайте надеяться, что этого все же не произойдет. Для того, чтобы предотвратить подобный сценарий, следует реализовать сеть с нулевым доверием (zero-trust), в которой весь трафик между сервисами зашифрован. Большинство современных сервисных сеток добиваются этого с помощью взаимного TLS (mutual TLS, mTLS). В некоторых случаях mTLS работает в целых облаках и кластерах (думаю, и межпланетные коммуникации когда-нибудь будут устроены аналогично).
Конечно, для mTLS service mesh необязательна. Каждый сервис может сам позаботиться о своем TLS, но это означает, что нужно будет найти способ генерировать сертификаты, распределять их по хостам сервиса, включать в приложение код, который будет загружать эти сертификаты из файлов. Да, еще не забудьте об обновлении этих сертификатов через определенные промежутки времени. Сервисные сетки автоматизируют mTLS с помощью систем вроде SPIFFE, которые, в свою очередь, автоматизируют процесс выпуска и ротации сертификатов.
3. Аутентификация и авторизация
TL;DR: Устанавливайте, кто является инициатором запроса, и определяйте, что им разрешено делать еще до того, как запрос достигнет сервиса.
Сервисы часто хотят знать, кто выполняет запрос (аутентификация), и, используя эту информацию, решают, что данному субъекту разрешено делать (авторизация). В данном случае за местоимением «кто» могут скрываться:
4. Балансировка нагрузки
TL;DR: Распределяйте нагрузку по экземплярам сервиса по определенному шаблону.
Классические балансировщики имеют и другие функции, такие как кэширование HTTP и защита от DDoS, но они не очень актуальны для трафика типа east-west (т.е. для трафика, текущего в пределах датацентра ― прим. перев.)(типичная область применения service mesh). Конечно, не обязательно использовать service mesh для балансировки нагрузки, однако она позволяет задавать и контролировать политики балансировки для каждого сервиса из централизованного управляющего слоя, тем самым устраняя необходимость запускать и настраивать отдельные балансировщики в сетевом стеке.
5. Разрыв цепи (circuit breaking)
TL;DR: Останавливайте трафик к проблемному сервису и контролируйте ущерб при наихудших сценариях.
Если по какой-либо причине сервис не справляется с трафиком, service mesh предоставляет несколько вариантов решения этой проблемы (о других будет рассказано в соответствующих разделах). Circuit breaking ― это самый жесткий вариант отключения сервиса от трафика. Однако сам по себе он не имеет смысла ― необходим запасной план. Может предусматриваться противодавление (backpressure) на сервисы, выполняющие запросы (только не забудьте настроить свою service mesh для этого!), или, например, окрашивание статус-страницы в красный цвет и перенаправление пользователей на очередной вариант страницы с «падающим китом» («Twitter is down»).
Сервисные сетки позволяют не только определять, когда последует отключение и что за этим последует. В данном случае «когда» может включать любую комбинацию заданных параметров: общее число запросов за некий период, количество параллельных подключений, pending-запросы, активные повторные попытки и т.д.
Вы вряд ли захотите злоупотреблять circuit breaking’ом, но приятно осознавать, что есть резервный план на крайний случай.
6. Автомасштабирование
TL;DR: Увеличивайте или уменьшайте число экземпляров сервиса в зависимости от заданных критериев.
Service mesh’и ― это не планировщики, поэтому они не осуществляют масштабирование самостоятельно. Однако они могут поставлять информацию, на основе которой планировщики будут принимать решения. Поскольку service mesh’и имеют доступ ко всему трафику между сервисами, они располагают обширной информацией о том, что происходит: какие сервисы столкнулись с проблемами, какие загружены совсем слабо (выделенные на них мощности тратятся впустую) и т.д.
7. Канареечные развертывания
TL;DR: Испытывайте новые функции или версии сервиса на подмножестве пользователей.
Скажем, вы разрабатываете некий SaaS-продукт и намереваетесь выкатить его новую крутую версию. Вы протестировали ее в staging, и она прекрасно отработала. Но все же одолевают определенные опасения насчет ее поведения в реальных условиях. Другими словами, требуется проверить новую версию на реальных задачах, не рискуя при этом доверием пользователей. Канареечные развертывания отлично подходят для этого. Они позволяют продемонстрировать новую функцию некоторому подмножеству пользователей. Это подмножество может состоять из самых лояльных пользователей или тех, кто работает с бесплатной версией продукта, или пользователей, выразивших желание побыть «подопытными кроликами».
Service mesh’и реализуют это, позволяя указать критерии, определяющие, кто и какую версию приложения увидит, и соответствующим образом маршрутизируя трафик. При этом для самих сервисов ничего не меняется. Версия 1.0 сервиса считает, что все запросы поступают от пользователей, которые именно ее и должны увидеть, а версия 1.1 то же самое полагает в отношении своих пользователей. А вы, тем временем, можете менять процент трафика между старой и новой версией, перенаправляя растущее число пользователей на новую, если она работает стабильно и ваши «подопытные» дают добро.
8. Сине-зеленые развертывания
TL;DR: Выкатывайте новую крутую функцию, но будьте готовы немедленно вернуть все назад.
Смысл сине-зеленых развертываний в том, чтобы выкатить новый «синий» сервис, запустив его параллельно со старым, «зеленым». Если все пойдет гладко и новый сервис хорошо себя зарекомендует, то старый можно будет постепенно отключить. (Увы, когда-нибудь и этот новый «синий» сервис повторит судьбу «зеленого» и исчезнет…) Сине-зеленые развертывания отличаются от канареечных тем, что новая функция охватывает сразу всех пользователей (а не часть); смысл здесь в том, чтобы иметь наготове «запасную гавань», если вдруг что-то пойдет не так.
Service mesh’и предлагают очень удобный способ тестирования «синего» сервиса и мгновенного переключения на рабочий «зеленый» в случае неполадок. Не говоря уже о том, что попутно они дают массу информации (см. пункт «Телеметрия» ниже) о работе «синего», которая помогает понять, готов ли тот к полноценной эксплуатации.
Прим. перев.: Подробнее о разных стратегиях развертывания в Kubernetes (включая упомянутые canary, blue/green и другие) можно почитать в этой статье.
9. Проверка здоровья
TL;DR: Следите за тем, какие экземпляры сервисов работоспособны, и реагируйте на те из них, которые таковыми быть перестают.
Таким образом, проверка здоровья выступает не самостоятельным сценарием использования, а обычно используется для достижения других целей. Также, в зависимости от результатов health check’ов, могут потребоваться внешние (по отношению к другим целям сервисных сеток) действия: например, обновлять страницу состояния, создавать issue на GitHub или заполнять тикет JIRA. И service mesh предлагает удобный механизм для автоматизации всего этого.
10. Перебрасывание нагрузки (load shedding)
TL;DR: Перенаправляйте трафик в ответ на временный всплеск в использовании.
Если некий сервис оказывается перегружен трафиком, вы можете временно перенаправить часть этого трафика в другое место (то есть «сбросить», «перелить» (shed) его туда). Например, в резервный сервис или дата-центр, или в постоянный Pulsar topic. В результате, сервис продолжит обрабатывать часть запросов вместо того, чтобы упасть и перестать обрабатывать вообще все. Сбрасывание нагрузки предпочтительнее, чем разрыв цепи, но все равно нежелательно злоупотреблять им. Оно позволяет предотвратить каскадные сбои, в результате которых падают downstream-сервисы.
11. Распараллеливание/зеркалирование трафика
TL;DR: Отправляйте один запрос сразу в несколько мест.
Еще один связанный сценарий использования сервисной сетки, который можно реализовать поверх распараллеливания трафика, ― это регрессионное тестирование. Оно предусматривает отправку одних и тех же запросов различным версиям сервиса и проверку того, ведут ли все версии себя одинаково. Мне пока не встречалась реализация service mesh с интегрированной системой регрессионного тестирования вроде Diffy, но сама идея кажется перспективной.
12. Изоляция
TL;DR: Разбивайте свою service mesh на мини-сети.
Также известная как сегментация, изоляция ― это искусство разделения сервисной сетки на логически обособленные сегменты, которые ничего не знают друг о друге. Изоляция немного похожа на создание виртуальных частных сетей. Принципиальная же разница состоит в том, что вы по-прежнему можете пользоваться всеми преимуществами service mesh (вроде обнаружения сервисов), но с дополнительной безопасностью. Например, если злоумышленник сумеет проникнуть в сервис в одной из подсетей, он не сможет увидеть, какие сервисы запущены в других подсетях, или перехватить их трафик.
Кроме того, преимущества могут быть и организационными. Возможно, вам захочется разбить сервисы на подсети в зависимости от структуры компании и освободить разработчиков от когнитивной нагрузки, вызванной необходимость держать в уме всю service mesh.
13. Ограничение частоты запросов, повторные попытки и тайм-ауты
TL;DR: Больше не надо включать в кодовую базу насущные задачи по управлению запросами.
Все эти вещи можно было бы рассматривать как отдельные случаи использования, но я решил объединить их из-за одной общей особенности: они перенимают на себя задачи по управлению жизненным циклом запросов, обычно отрабатываемые библиотеками приложений. Если вы разрабатываете веб-сервер на Ruby on Rails (не интегрированный с service mesh), который выполняет запросы к backend-сервисам через gRPC, приложение должно будет само решать, что делать, если N запросов завершатся неудачей. Также придется выяснять, какой объем трафика способны будут обработать эти сервисы и за’hardcode’ить эти параметры с помощью специальной библиотеки. Плюс ко всему, приложение должно будет решать, когда пора сдаться и позволить запросу протухнуть (по timeout). И для того, чтобы изменить любой из вышеперечисленных параметров, веб-сервер придется остановить, переконфигурировать и запустить заново.
Передача этих задач сервисной сетке означает не только то, что разработчикам сервисов не нужно будет думать о них, но и то, что их можно будет рассматривать более глобальным образом. Если используется сложная цепочка сервисов, скажем, A –> B –> C –> D –> E, необходимо учитывать весь жизненный цикл запроса. Если стоит задача продлить тайм-ауты в сервисе С, логично делать это все разом, а не по частям: обновив код сервиса и дожидаясь, пока pull request будет принят и CI-система развернет обновленный сервис.
14. Телеметрия
TL;DR: Собирайте всю нужную (и не совсем) информацию от сервисов.
Телеметрия ― это общий термин, включающий в себя метрики, распределенную трассировку и логи. Сервисные сетки предлагают механизмы для сбора и обработки всех трех типов данных. Здесь все становится немного расплывчатым, поскольку число возможных вариантов слишком велико. Для сбора метрик есть Prometheus и другие инструменты, для сбора логов можно использовать fluentd, Loki, Vector и др. (например, ClickHouse с нашим loghouse для K8s — прим. перев.), для распределенной трассировки есть Jaeger и т.п. Каждая service mesh может поддерживать одни инструменты и не поддерживать другие. Любопытно будет посмотреть, сможет ли проект Open Telemetry обеспечить некоторую конвергенцию.
В данном случае преимущество технологии service mesh в том, что sidecar-контейнеры могут, в принципе, собрать все вышеперечисленные данные со своих сервисов. Другими словами, в свое распоряжение вы получаете единую систему сбора телеметрии, и service mesh может обрабатывать все эту информацию различными способами. Например:
15. Аудит
TL;DR: Тот, кто забывает уроки истории, обречен их повторять.
Аудит ― это искусство наблюдения за важными событиями в системе. В случае service mesh это может означать отслеживание того, кто делал запросы к конкретным endpoint’ам определенных сервисов или сколько раз за последний месяц происходило некое событие, имеющее отношение к безопасности.
Понятно, что аудит очень тесно связан с телеметрией. Разница же состоит в том, что телеметрия обычно ассоциируется с такими вещами, как производительность и техническая корректность, в то время как аудит может иметь отношение к юридическим и другим вопросам, выходящим за рамки строго технической сферы (например, соответствие требованиям GDPR ― Общего регламента ЕС по защите данных).
16. Визуализация
TL;DR: Да здравствует React.js ― неистощимый источник причудливых интерфейсов.
Возможно, есть более подходящий термин, но я его не знаю. Я просто имею в виду графическое представление service mesh или ее некоторых компонентов. Эти визуализации могут включать индикаторы вроде средних задержек, информацию о конфигурации sidecar-контейнеров, результаты проверок здоровья и оповещения.
Работа в сервис-ориентированной среде сопряжена с гораздо более сильной когнитивной нагрузкой по сравнению с Его Величеством Монолитом. Поэтому когнитивное давление следует снижать любой ценой. Банальный графический интерфейс для service mesh с возможностью кликнуть на кнопку и получить нужный результат может иметь решающее значения для роста популярности этой технологии.
Не были включены в список
Изначально я намеревался включить в список еще несколько сценариев использования, но потом решил не делать этого. Вот они вместе с причинами моего решения:
Заключение
На этом пока все! Опять же, этот список весьма условен и, скорее всего, неполон. Если вам кажется, что я что-то упустил, или в чем-то ошибся, обращайтесь ко мне в Twitter (@lucperkins). Пожалуйста, соблюдайте правила приличия.
P.S. от переводчика
В качестве основы для заглавной иллюстрации к статье взято изображение из статьи «What is a Service Mesh (and when to use one)?» (автор — Gregory MacKinnon). На нем показано, как часть функциональности из приложений (зеленым цветом) перешла к service mesh, обеспечивающей взаимосвязи между ними (голубой цвет).